


Robots do not just look different. They also act through different physical control languages: different kinematics, sensors, action conventions, and timing. Being-H0.5 is our attempt to make one Vision-Language-Action model travel across those differences without turning into a brittle collection of per-robot hacks.
Overview
The intuition we kept coming back to is simple. Human interaction has rich structure that stays meaningful across hardware. If we can learn that structure as a reusable manipulation grammar, then a lot of cross-embodiment transfer becomes a translation problem rather than a reinvention problem.
A Shared Action Language
Most transfer failures start with something mundane. One robot uses end-effector deltas. Another uses joint targets. A dexterous hand adds many more degrees of freedom. Even when two actions mean the same intent, their parameterization can make them look unrelated. So we map all embodiments into a single physically interpretable vector space with semantically aligned slots. End-effector pose, joint positions, gripper or finger articulation, and base control all live in one shared vocabulary. We treat human hand motion as a first-class embodiment in the same vocabulary. That lets human interaction traces provide supervision that is directly relevant to robot control.
Architecture
Being-H0.5 uses a Mixture-of-Transformers design. We keep a strong multimodal understanding pathway and a strong action pathway, and we tie them together through shared attention and the unified state-action interface.
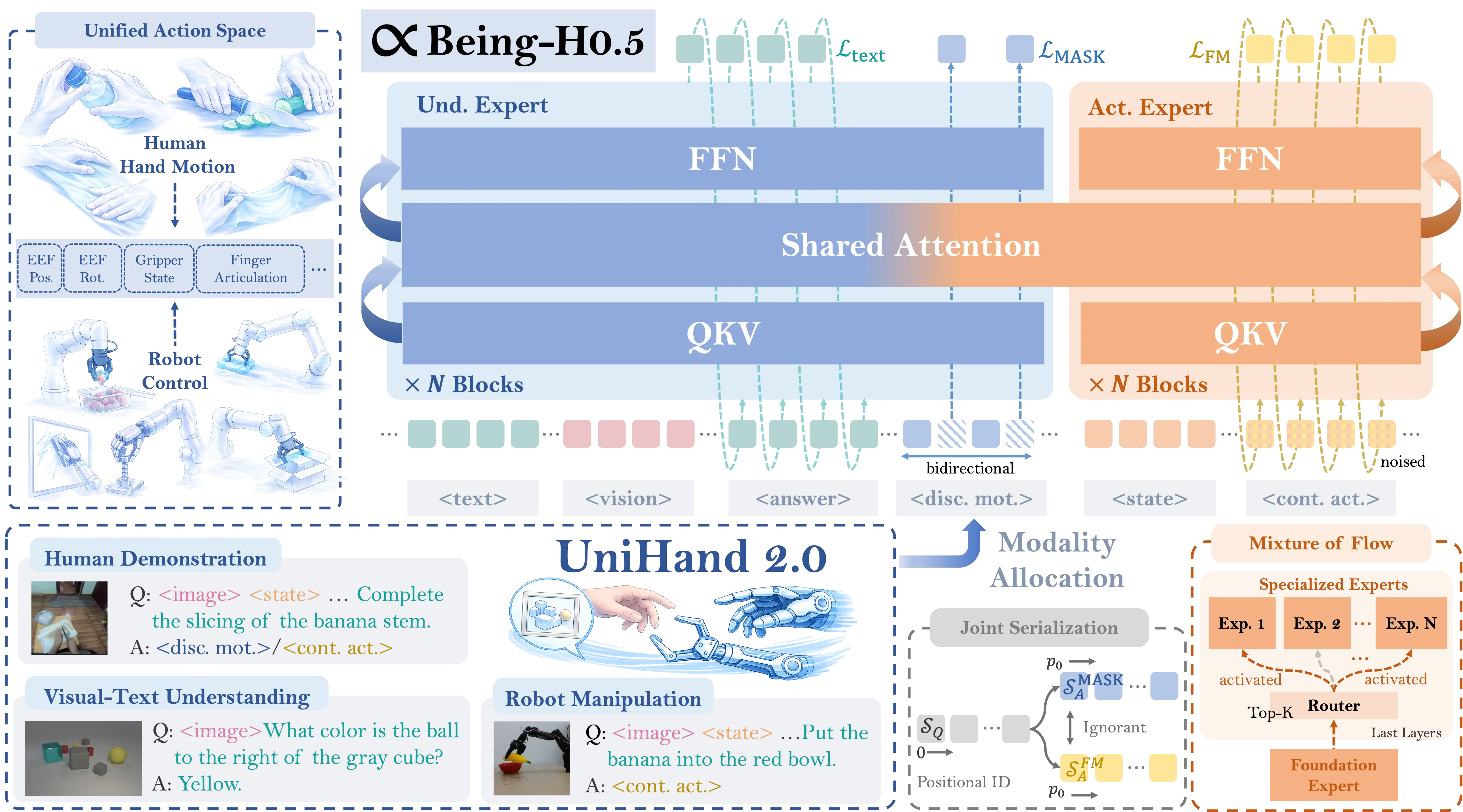
Mixture of Flow
A unified action language makes sharing possible, but it also forces the model to cover very different dynamics. The action expert needs enough capacity to handle a low-DoF gripper and a high-DoF dexterous hand without collapsing into negative transfer. We introduce Mixture of Flow (MoF) to keep two things true at once. Shared layers learn transferable motor primitives. Routed specialists capture embodiment-specific and task-specific dynamics. The routing is sparse, so capacity scales without paying dense inference cost.
UniHand-2.0 Pretraining
If you only train on robot trajectories, you often end up with a policy that is competent but shallow. It reacts well in-distribution, then breaks when the scene is slightly different. Human interaction traces add a different kind of signal: contact-rich behavior across diverse contexts. UniHand-2.0 is the pretraining mixture we built to make that signal usable. It combines human demonstrations, robot manipulation, and vision-language supervision so the model keeps high-level grounding while learning actionable manipulation structure.
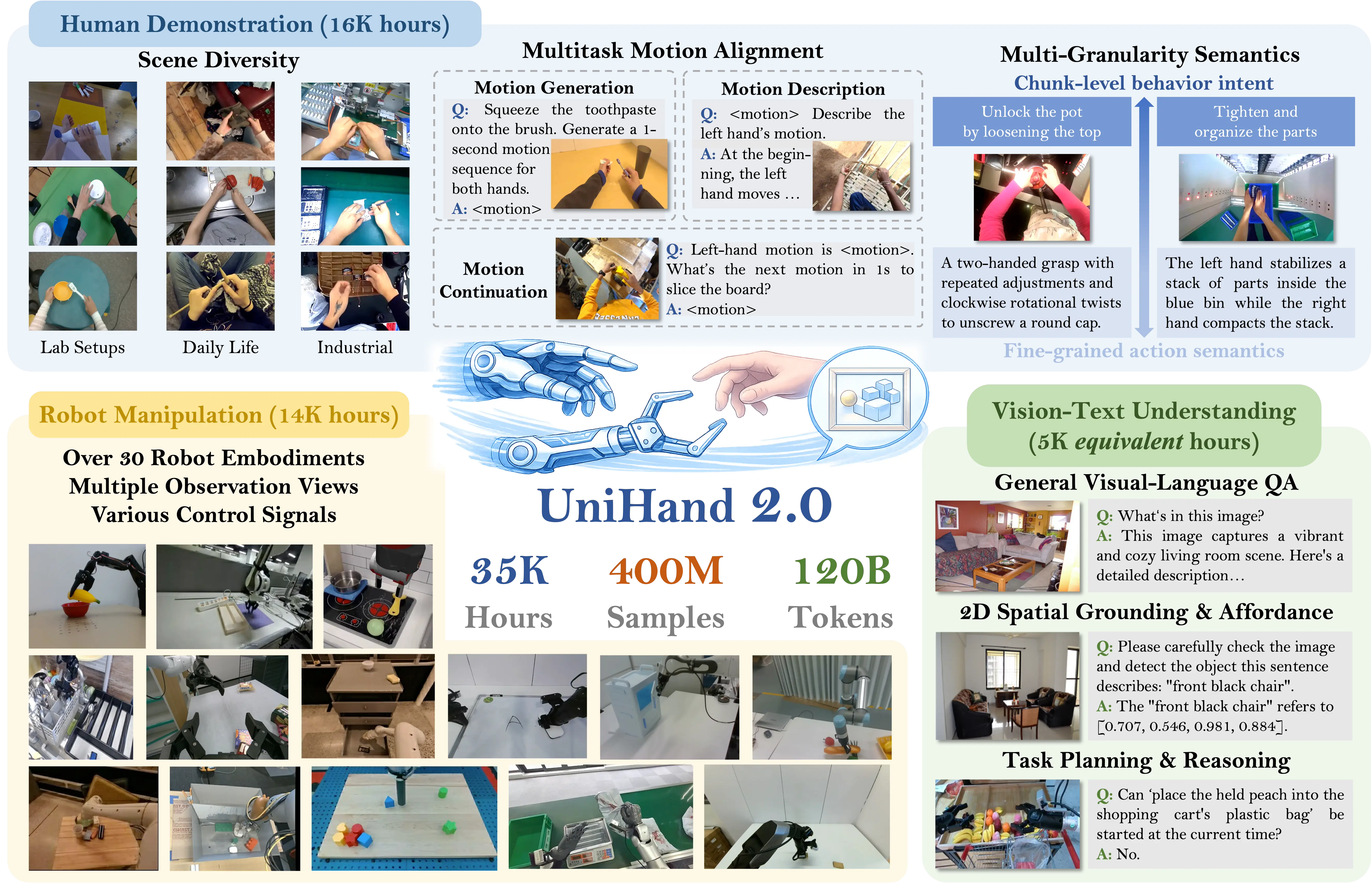
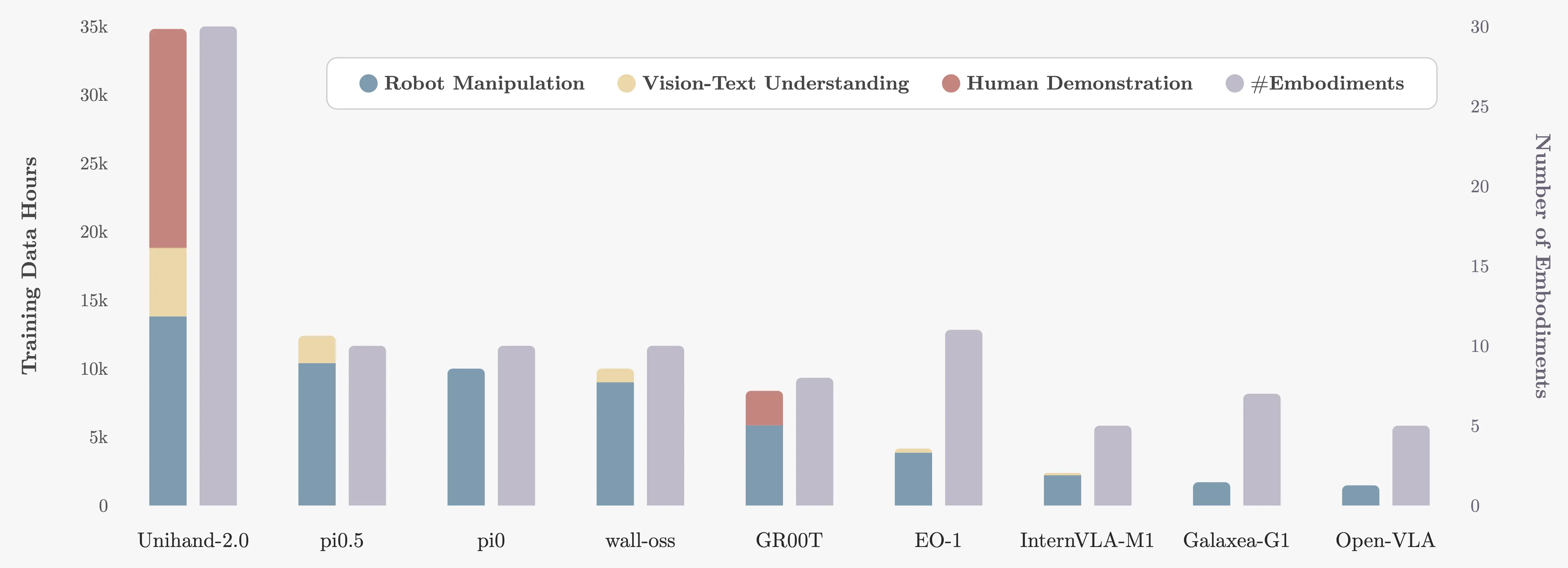
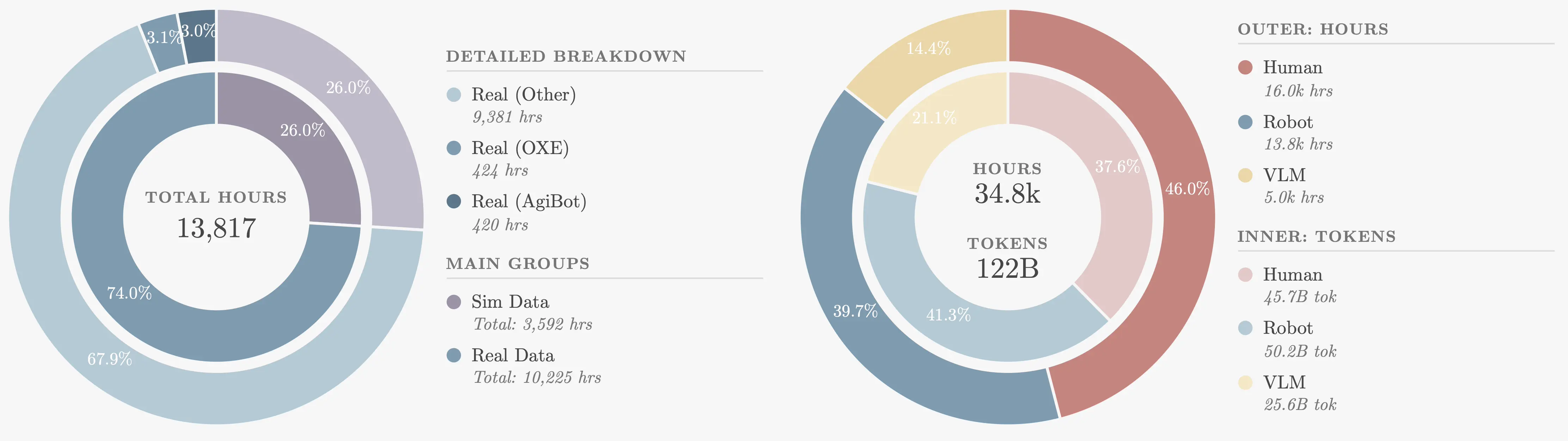
One small, opinionated choice matters more than it sounds. We cap simulation rather than letting it dominate, because sim teaches policies to rely on its own shortcuts. We still want sim for coverage, but we do not want it to define the action manifold.
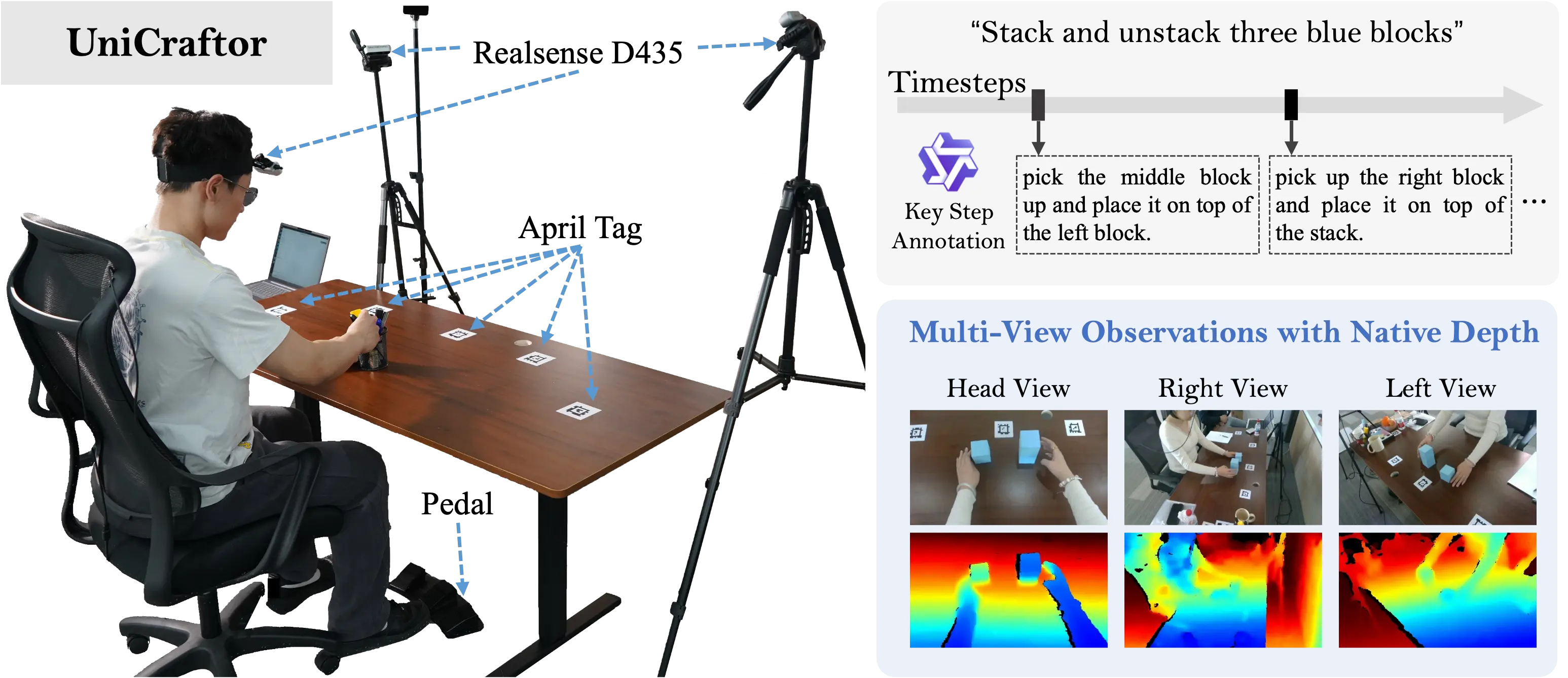
UniCraftor Data Collection
A lot of public data is missing signals that are expensive to recover later. Depth is unreliable. Extrinsics drift. Key interaction moments are not timestamped. That does not always prevent learning, but it makes stable manipulation harder than it needs to be. We build UniCraftor, a portable system that makes those signals easy to collect. Native RGB-D provides geometry that survives occlusion. Calibration keeps trajectories and observations in a consistent world frame. Simple event triggers capture contact and release moments precisely.
Post-training and Deployment
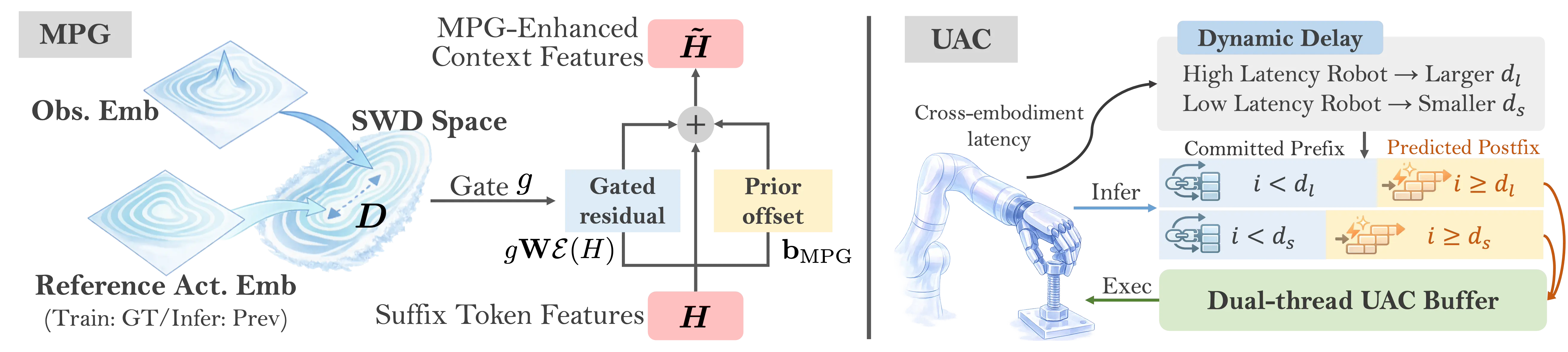
Pretraining gives broad priors. Post-training is where the model has to obey your hardware, your latency, and your control rate. This is also where we found that cross-embodiment transfer can look good on paper and still fail in practice. We address three issues. Embodiment mismatch is handled with Embodiment-Specific Adaptation, updating only the active action slots instead of building a new head per robot. Perception shift is handled with Manifold-Preserving Gating, suppressing unreliable context so iterative refinement stays on a stable action manifold. Asynchronous execution is handled with Universal Async Chunking, training the policy to remain consistent across different delays and rates.
Results
Real Robots
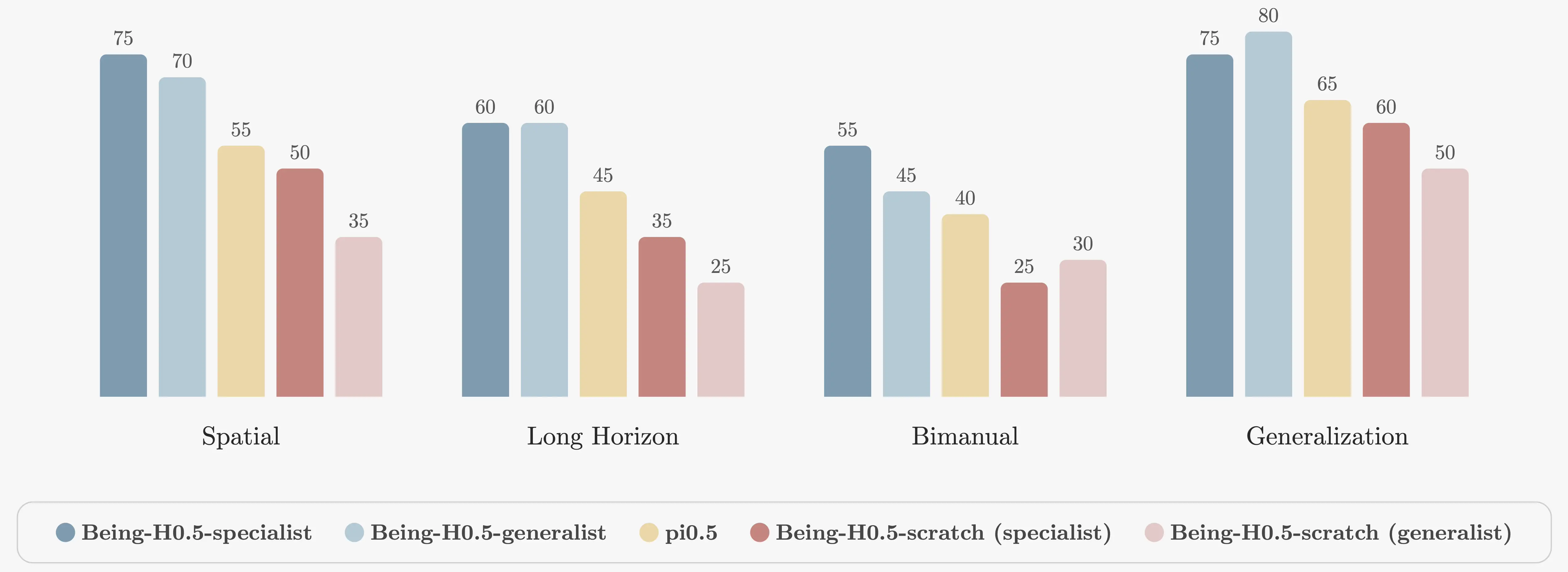
We evaluate across five embodiments and ten tasks spanning spatial, long-horizon, bimanual, and generalization suites. First, a single generalist checkpoint stays close to specialist performance more often than we expected. Second, the ablations show what breaks first: long-horizon and bimanual tasks are where robustness and timing assumptions get exposed.
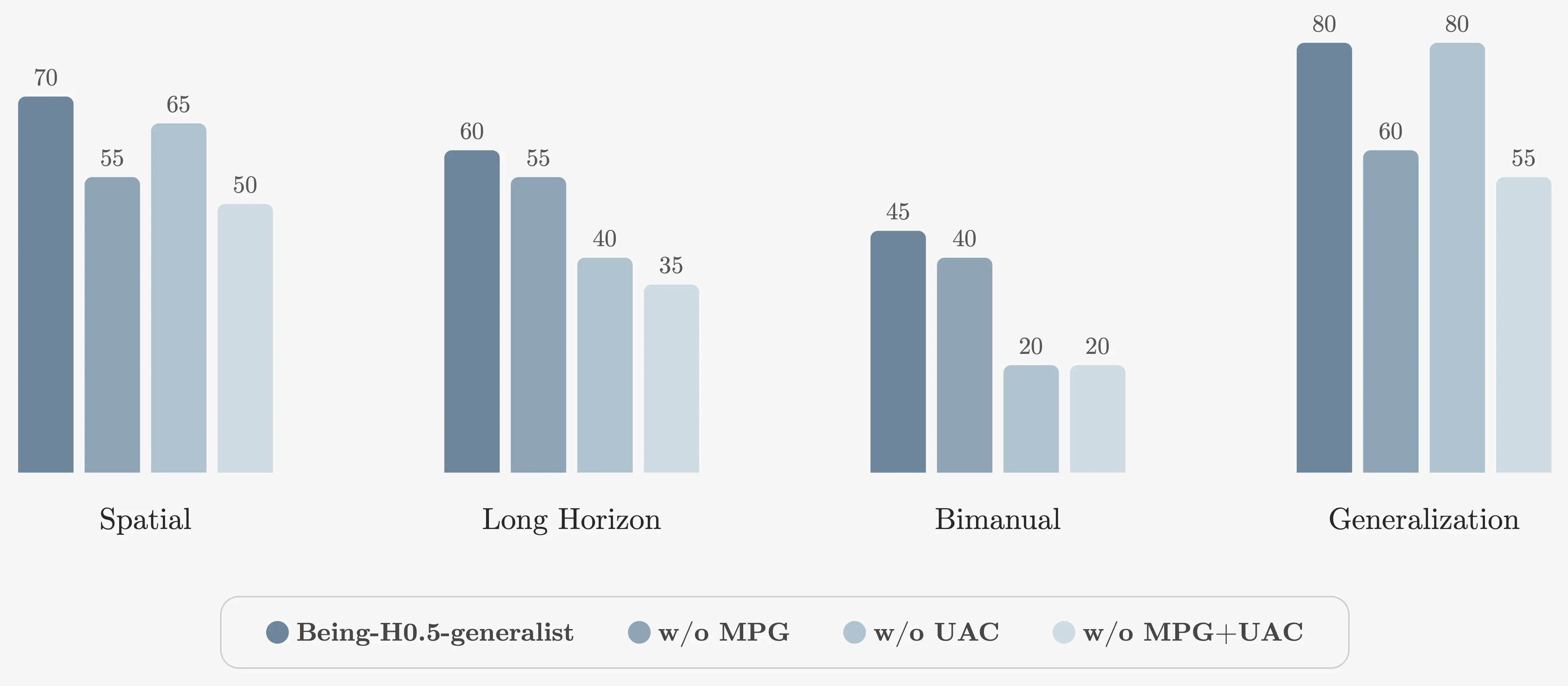
Simulation Benchmarks
We also report standard benchmarks with a deliberately lean setup. RGB-only inputs at 224 by 224 resolution. A 2B backbone. Even with that, Being-H0.5 reaches 98.9 percent on LIBERO in the specialist setting and 97.6 percent in the generalist setting, and 53.9 percent on RoboCasa Human-50 in the specialist setting and 53.3 percent in the generalist setting.
A Surprise We Care About
During real-robot evaluation, we saw a small but consistent signal that matters to us. After cross-embodiment post-training, the generalist checkpoint sometimes initiates the right multi-step structure on task and embodiment combinations it never saw paired during training. We do not present this as a solved problem. But we think it is a useful signpost. When the action interface stays unified and post-training data grows in diversity, transfer can start to look like something that emerges rather than something you engineer case by case.
Takeaway
Being-H0.5 is a bet on one scaling direction. Use human interaction traces to learn reusable manipulation structure. Use a unified action language to make that structure portable. Then design capacity and deployment mechanisms so the same story survives a real control loop.
Citation
@article{beingbeyond2026beingh05,
title={Being-H0. 5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization},
author={Luo, Hao and Wang, Ye and Zhang, Wanpeng and Zheng, Sipeng and Xi, Ziheng and Xu, Chaoyi and Xu, Haiweng and Yuan, Haoqi and Zhang, Chi and Wang, Yiqing and others},
journal={arXiv preprint arXiv:2601.12993},
year={2026}
}