

Robot control needs more than a direct mapping from pixels to torques, and it also needs more than a slow imagination loop that rolls out future frames before every move. With Being-H0.7, we asked whether a robot policy can reason about future interaction in a compact latent space, then act immediately without explicit future-image generation at test time.
The result is a latent world-action model trained from large-scale egocentric videos. It keeps the predictive value of world modeling, but expresses that value through a deployable latent action prior rather than a pixel-space rollout.
Overview
Being-H0.7 is our current answer to a practical question in embodied AI: how do we make future-aware robot reasoning scale with internet-level human video, while still fitting inside a real control loop?
Why Latent World-Action Modeling
A standard VLA policy is efficient, but action supervision is sparse. That makes it easy for the model to collapse many visually different situations into a small set of repeated behaviors. Video-based world models go after the opposite strength: they exploit dense future structure. But when that structure is represented as predicted pixels, inference becomes expensive and brittle, especially in dynamic or long-horizon manipulation.
Our view is that the missing interface is a compact reasoning space between multimodal understanding and dense action generation. Instead of forcing the model to jump directly from instruction and observations to low-level actions, we insert learnable latent queries that organize an intermediate world-action state.
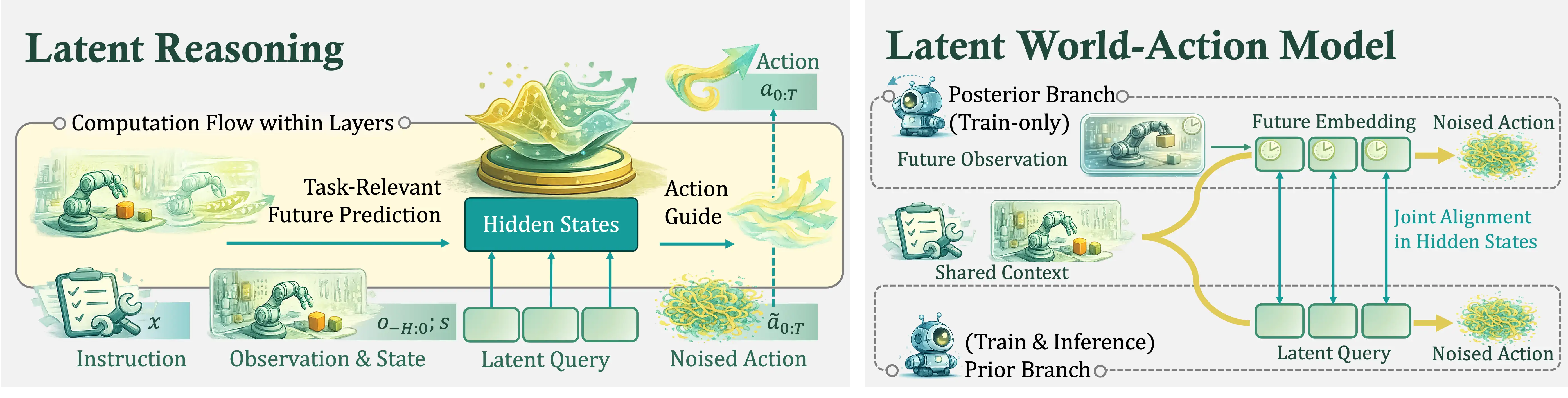
This latent space is where future-aware reasoning happens. At inference time, the model only uses the current instruction, observation history, state, and latent queries. During training, a matched posterior branch gets access to future observations, and we align the hidden states of the two branches in latent space. That lets the deployable branch absorb future-relevant structure without needing future frames at test time.
A Compact, Deployable Architecture
The architecture keeps this idea simple and efficient. We do not run two entirely separate networks. Instead, we pack the prior and posterior branches into a single sequence with shared context and a dual-branch attention mask. The prior branch uses learnable latent queries. The posterior branch replaces those positions with compact future embeddings of the same shape.
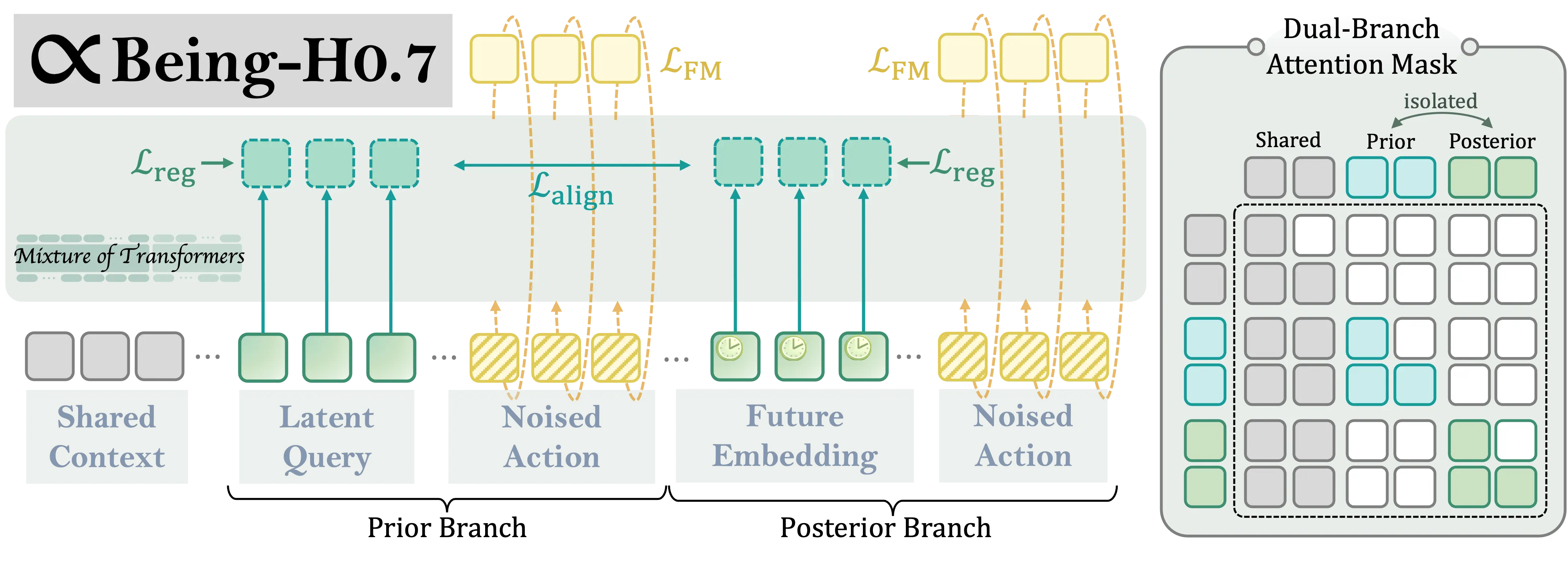
This matters because we care about scaling. Being-H0.7 is trained on 200,000 hours of egocentric human videos together with 15,000 hours of robot demonstrations. At that scale, a pixel-heavy imagine-then-act recipe becomes hard to justify. Latent world-action modeling gives us a way to use future structure without turning deployment into a video-generation problem.
Results Across Simulation and Real Robots
Simulation Benchmarks
Across six widely used simulation benchmarks, Being-H0.7 reaches the strongest overall performance and the best average rank. The more interesting point is the shape of that performance: standard tabletop control, perturbation robustness, bimanual dexterity, long-horizon sequencing, and zero-shot environment shift all move together rather than trading off against one another.
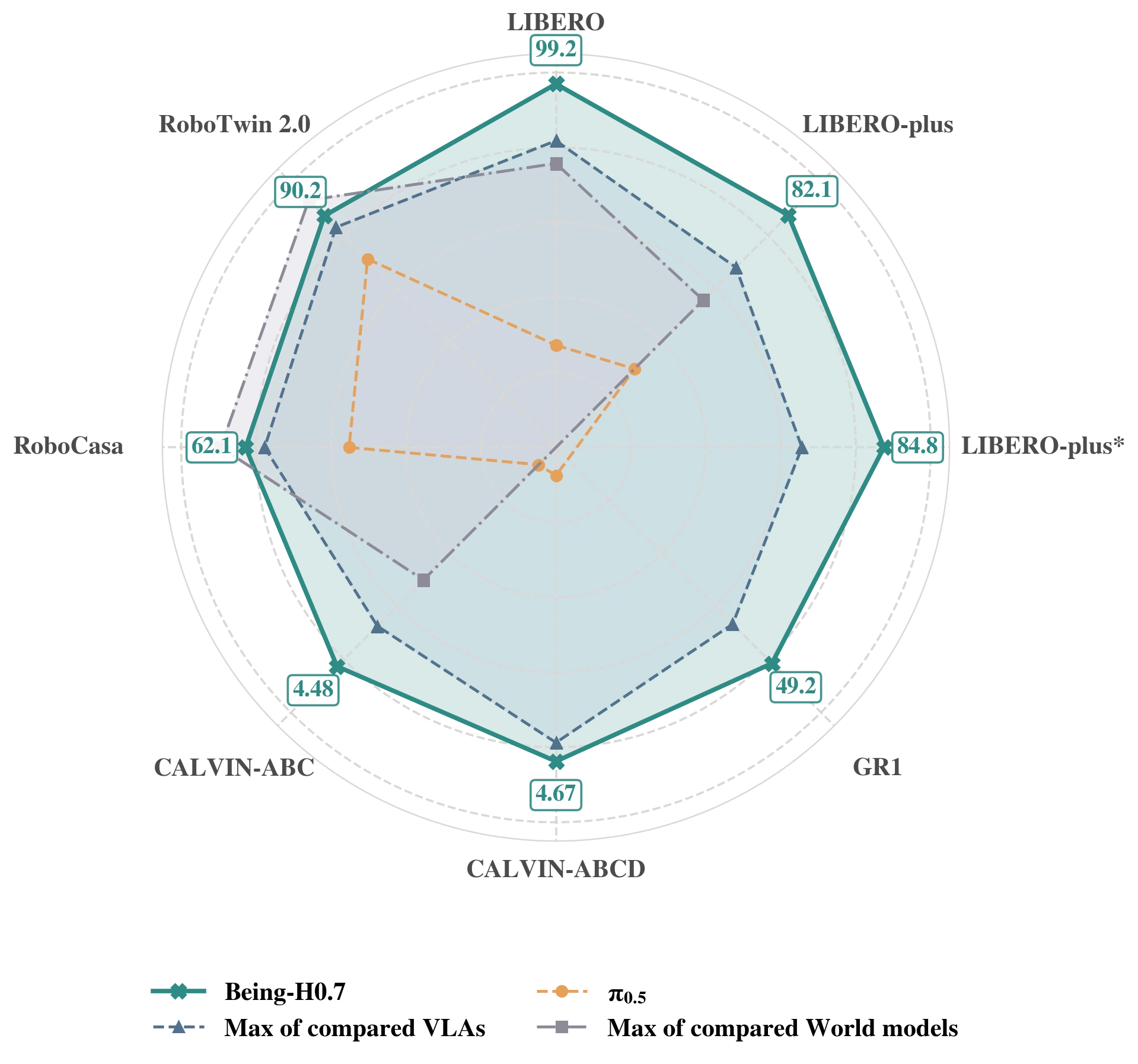
This view makes the result easier to read than a long benchmark-by-benchmark list. Being-H0.7 sits on or near the frontier across almost every axis at once, including LIBERO, both LIBERO-plus settings, GR1, and both CALVIN splits, while remaining highly competitive on RoboCasa and Robotwin2. We read this as evidence that the latent prior is not tuned to one narrow control regime. It supports broad action quality across different task structures and embodiment assumptions.
Real-World Evaluation
Simulation is useful, but the real question is whether the policy survives contact with moving objects, fluids, deformables, and timing-sensitive interaction.
For that reason, we built a new real-world evaluation around 12 tasks, 3 robot platforms, and 5 ability-oriented suites:
Dynamic Scene, Physical Reasoning, Motion Reasoning, Long Horizon, and Generalization.
The deployments span PND Adam-U, Unitree G1, and Franka FR3, all equipped with Linkerbot O6 hands.

The task set is intentionally varied. It includes fast rolling-ball catching, racket redirection, pipette transfer, funnel pouring, sorting from a moving conveyor, deformable garment folding, shoe-tree insertion, shoe boxing, multi-level drawer sorting, and hammer-and-nail interaction. Together, the 12 scenes force the policy to react quickly, reason about physical consequences, maintain multi-stage consistency, and transfer across layouts and platforms.

At the suite level, Being-H0.7 leads across all five task suites against Being-H0.5, Pi0.5, and Fast-WAM. That breadth is the main real-world result. The gain is not isolated to one carefully chosen showcase task. It appears on dynamic interaction, physical manipulation, motion-centric timing, longer sequential tasks, and cross-setting generalization.
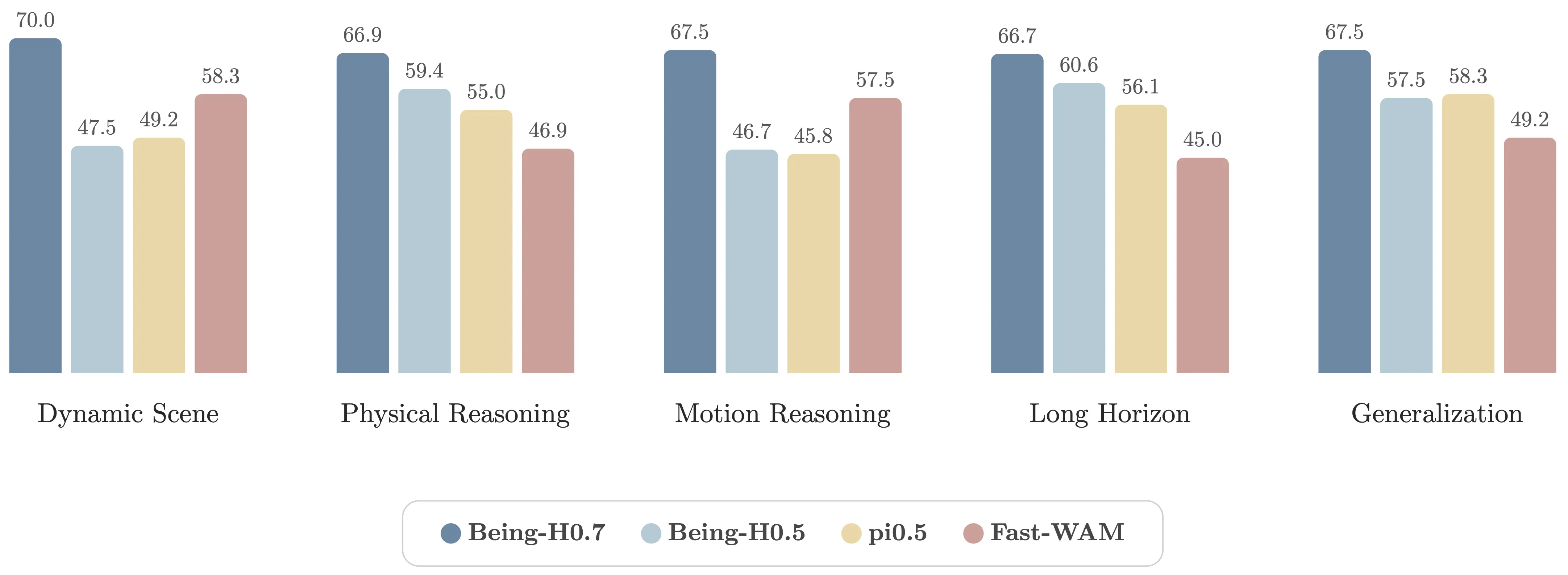
The pattern of the benchmark also tells us something more specific. Dynamic and motion-centric tasks are where explicit timing mistakes get punished immediately, so they are a strong test of whether the model has actually internalized future interaction structure. Physical and long-horizon tasks probe a different failure mode: whether the policy understands consequences that unfold over multiple stages, such as containment, deformable contact, tool use, or the cost of making an early mistake. Being-H0.7 holds up on both fronts.
Deployment Still Matters
A strong world-action model is only useful if the deployment stack stays lightweight enough for online control. We therefore pair chunked action prediction with Universal Async Chunking (UAC) on the client side. The idea is straightforward: keep a committed action prefix executing in real time, ask for the next chunk asynchronously, and only stitch the future suffix back into the buffer when it arrives. That keeps the robot moving smoothly even when model, transport, and scheduler latencies are not perfectly stable.
On Unitree G1, we further integrate a pretrained AMO policy as the balance-aware low-level whole-body backend. Being-H0.7 still exposes the same upper-body policy interface, while AMO handles the lower-body and waist control loop needed for stable humanoid execution.
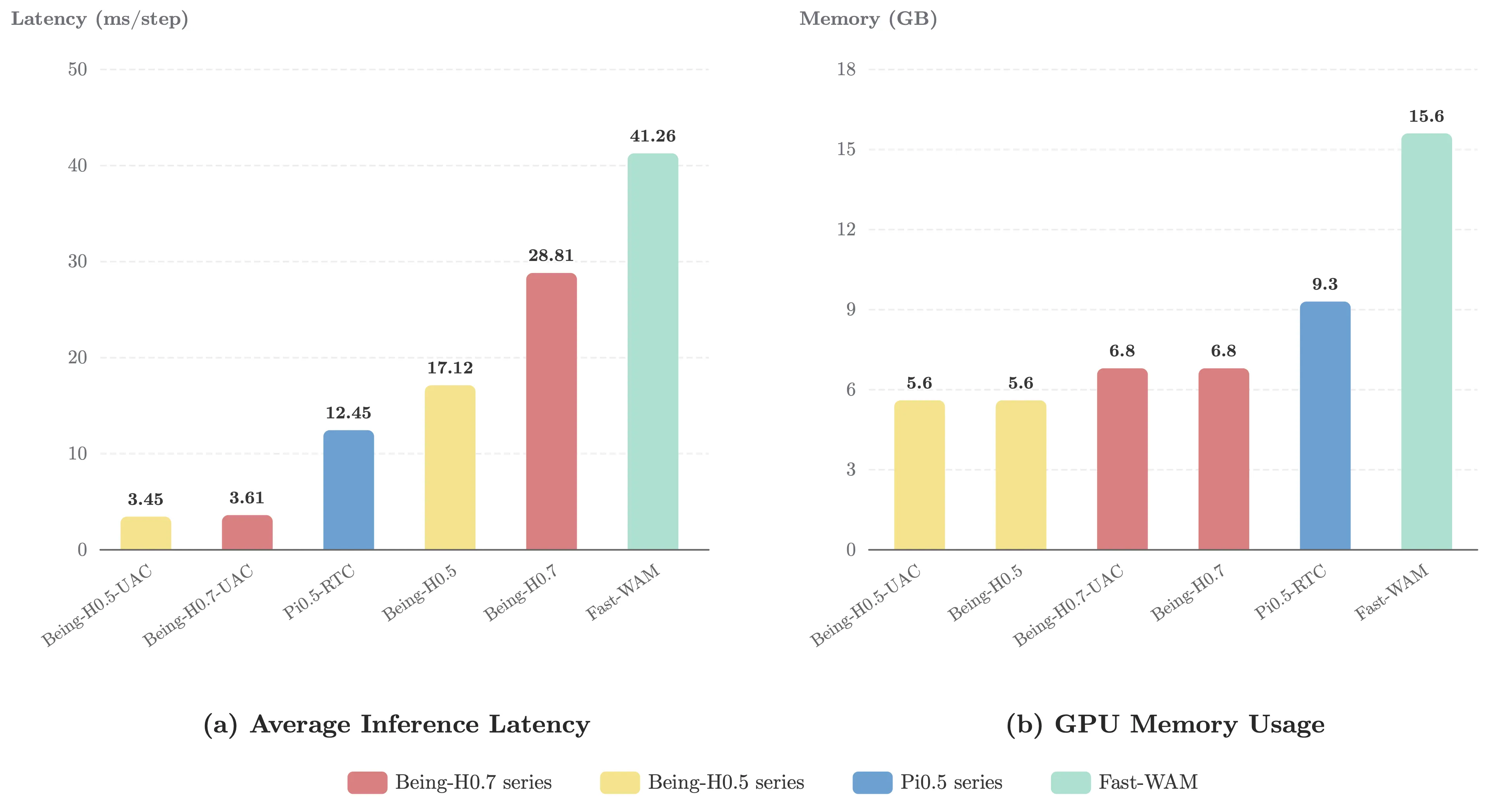
This systems behavior matters because it keeps the policy responsive enough for online manipulation. The gains from latent world-action modeling arrive together with an inference loop that remains light enough to deploy across real robot platforms.
Takeaway
Being-H0.7 is our attempt to make world modeling useful for robot control without inheriting the full cost of video generation. We use large-scale egocentric video to learn future-aware structure, compress that structure into a latent reasoning space, and deploy the resulting policy as a direct action model.
For us, the larger point is not only a better benchmark row. It is a cleaner recipe for scaling embodied intelligence: learn from far more human interaction, reason in a compact latent world-action space, and keep the final policy fast enough to matter in the real world.
Citation
@article{beingbeyond2026beingh07,
title={Being-H0. 7: A Latent World-Action Model from Egocentric Videos},
author={Luo, Hao and Zhang, Wanpeng and Feng, Yicheng and Zheng, Sipeng and Xu, Haiweng and Xu, Chaoyi and Xi, Ziheng and Fu, Yuhui and Lu, Zongqing},
journal={arXiv preprint arXiv:2605.00078},
year={2026}
}