

Multimodal LLMs often rely on modality-specific encoders, which makes vision tokens feel foreign to the language model. Being-VL-0 instead teaches the model a new visual vocabulary by applying Byte-Pair Encoding (BPE) directly on quantized image tokens. The result is a tokenizer that injects structural priors into the visual stream so the LLM can learn alignment more naturally.
Overview
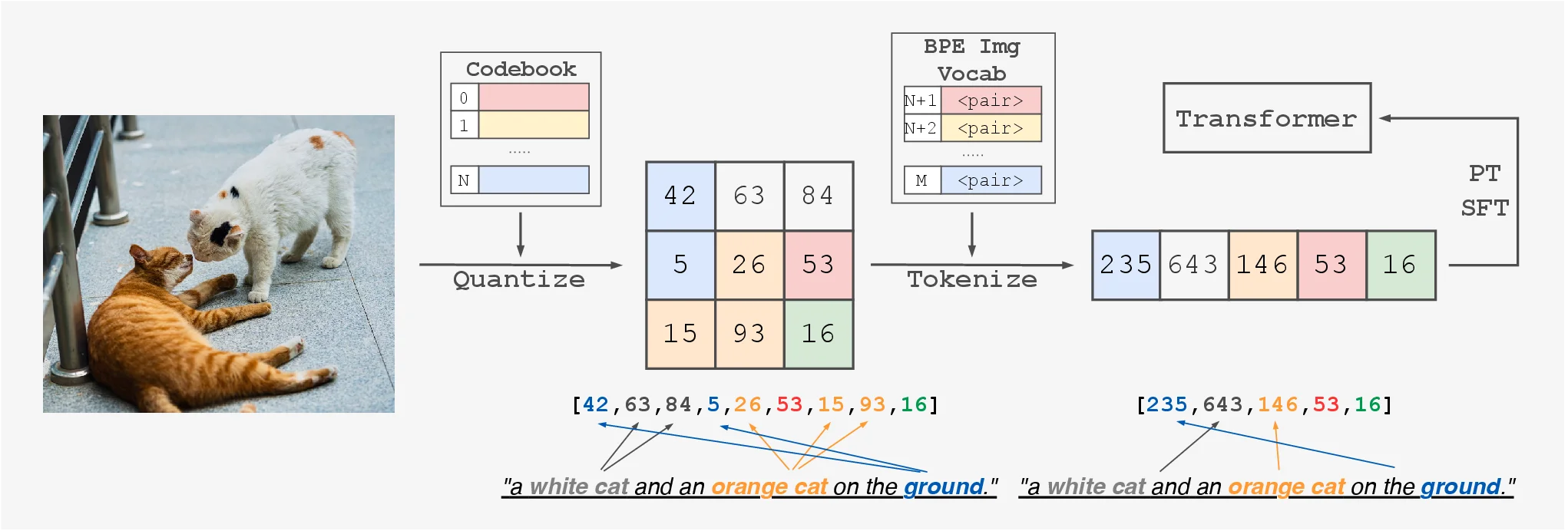
Why Tokenization Matters
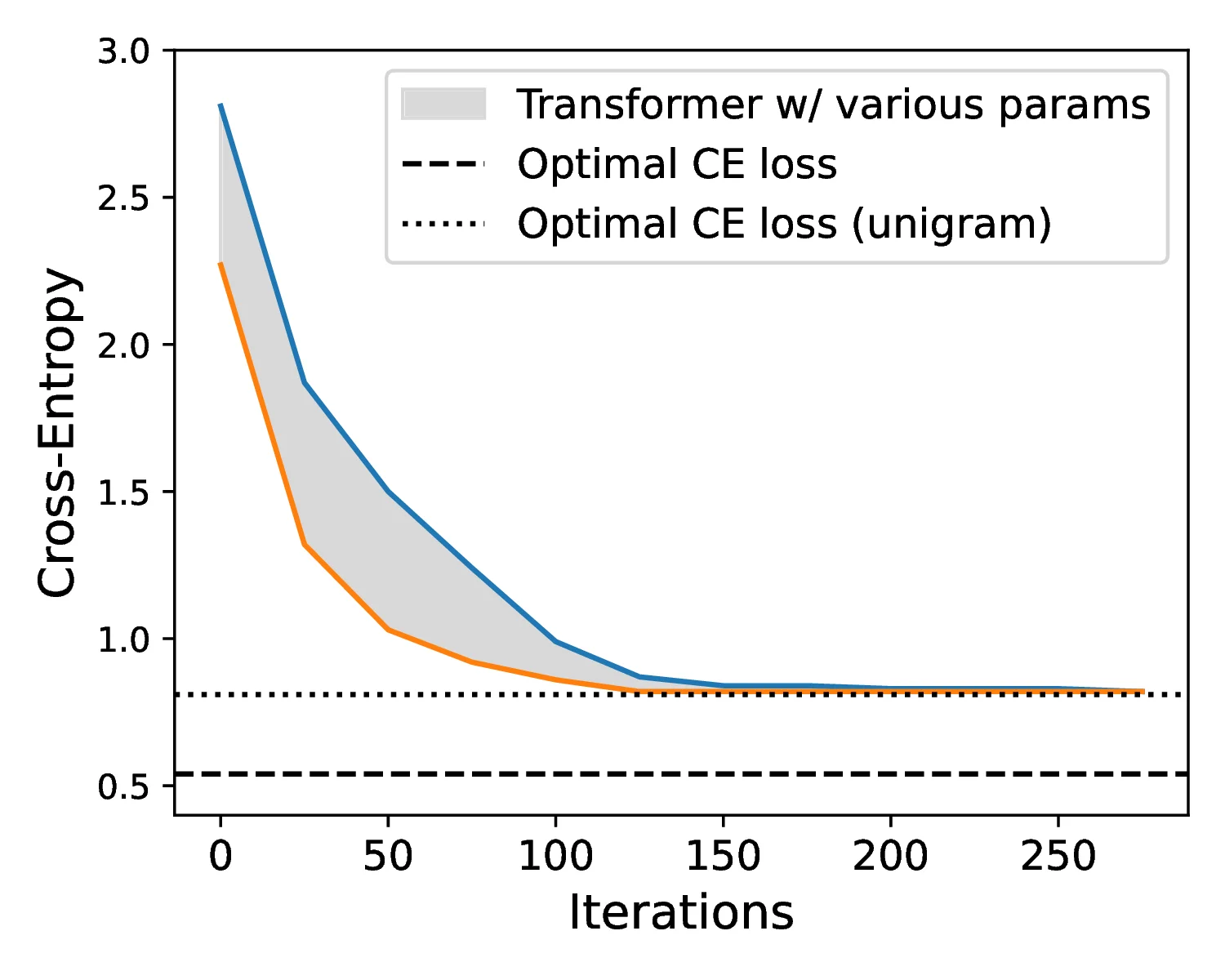
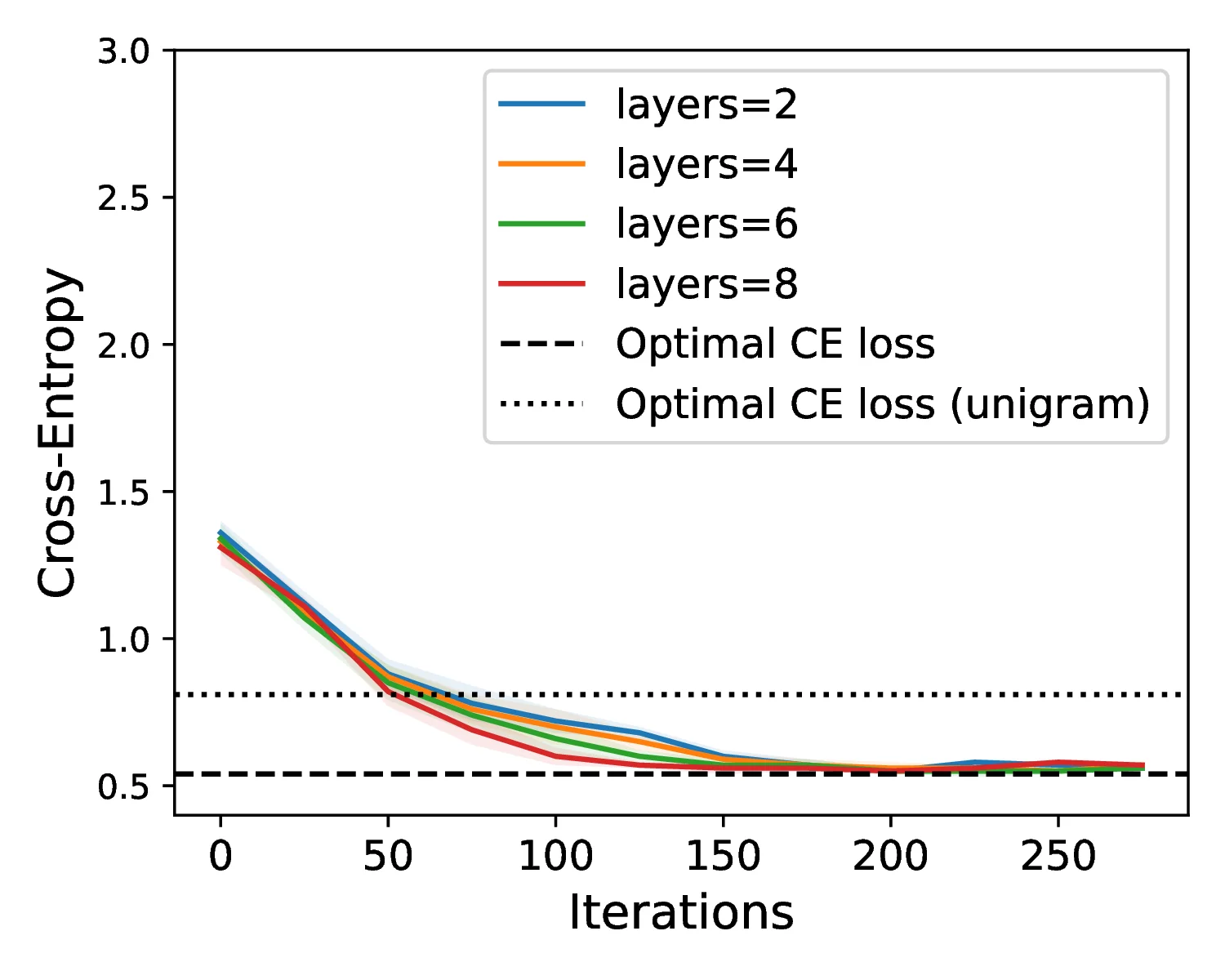
Our theoretical analysis shows that Transformers can collapse to unigram behavior on certain 2D sequence distributions. By explicitly merging visual tokens, BPE provides the missing structure and makes the learning problem tractable.
BPE Image Tokenizer
We build a 2D extension of BPE that merges frequent spatial token pairs across both horizontal and vertical directions. The tokenizer grows an extended vocabulary on top of the VQ-GAN codebook, producing composite visual tokens that encode structure. These tokens are then concatenated with text tokens in a single sequence, allowing the LLM to learn cross-modal reasoning end-to-end.
Training Recipe
Being-VL-0 uses a two-stage training pipeline on top of Llama-3.1-8B:
- Image understanding pretraining (PT): freeze text embeddings and learn the new image token embeddings from captioned data.
- Supervised fine-tuning (SFT): unfreeze all parameters and train on multi-turn vision-language instruction data.
This mirrors the intuition from text LLMs: learn a tokenizer-aware embedding first, then scale to richer reasoning data.
Results at a Glance
Across VQAv2, MMBench, MME, POPE, and VizWiz, BPE tokenization consistently improves over VQ-only baselines. The gains are strongest when the text embeddings are frozen during pretraining, suggesting cleaner visual grounding. Additional data scaling further lifts performance, indicating the approach has headroom.
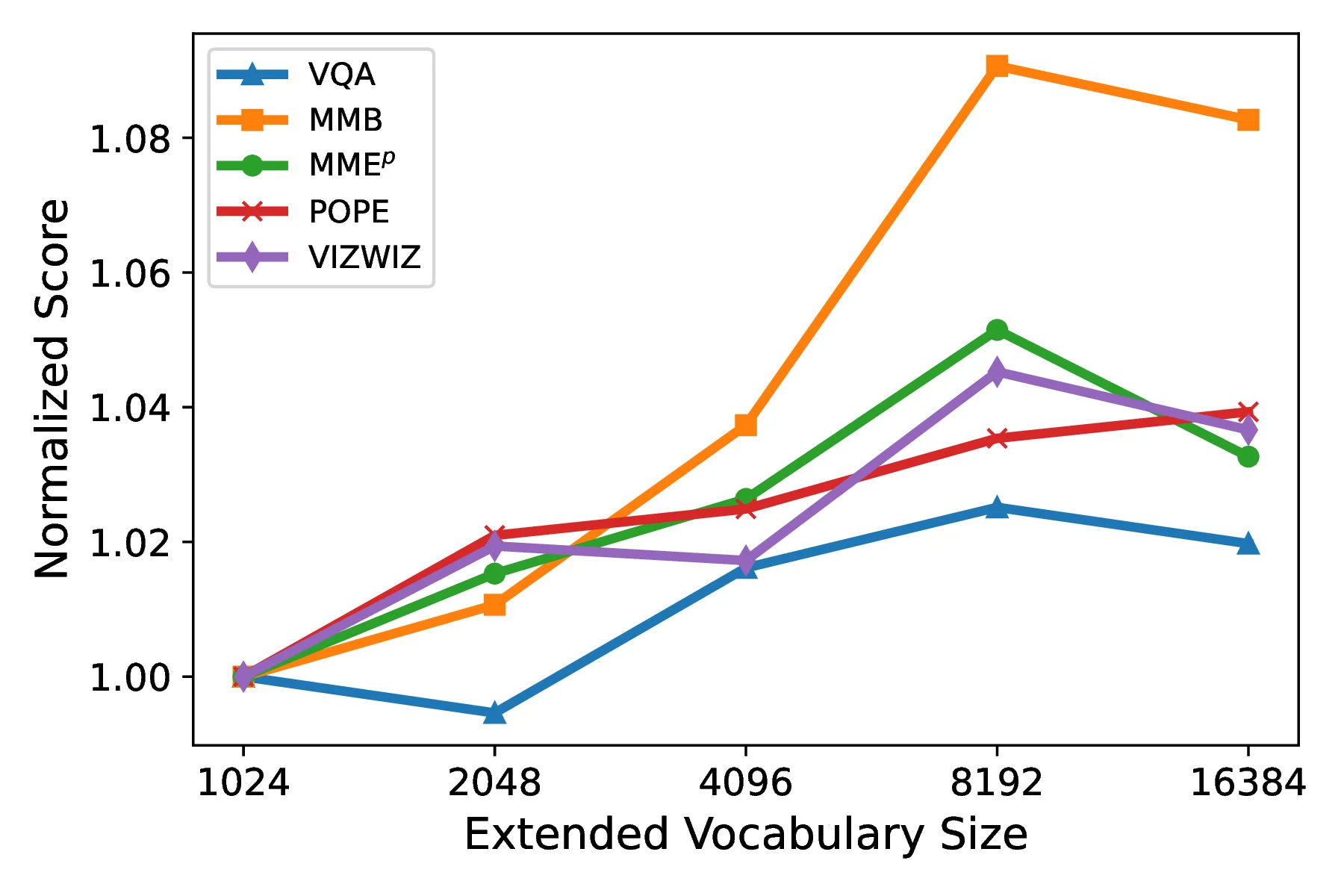
Vocabulary Size and Token Usage
We study how the BPE vocabulary size affects performance and how the model distributes weight across original VQ tokens versus merged tokens. The sweet spot appears near an 8K extended vocabulary, balancing fine-grained details with higher-level semantics.
Takeaway
Being-VL-0 shows that tokenization is not just a compression trick for multimodal models. By making visual tokens compositional and structure-aware, we can turn a text LLM into a stronger multimodal reasoner with less data.
Citation
@inproceedings{zhang2025pixelstokens,
title={From Pixels to Tokens: Byte-Pair Encoding on Quantized Visual Modalities},
author={Zhang, Wanpeng and Xie, Zilong and Feng, Yicheng and Li, Yijiang and Xing, Xingrun and Zheng, Sipeng and Lu, Zongqing},
booktitle={International Conference on Learning Representations},
year={2025}
}