

We present Being-VL-0.5, a framework that unifies multimodal understanding by applying byte-pair encoding to visual tokens.
Abstract
Multimodal large language models (MLLMs) have made significant progress in vision-language understanding, yet effectively aligning different modalities remains a fundamental challenge. We present a framework that unifies multimodal understanding by applying byte-pair encoding to visual tokens. Unlike conventional approaches that rely on modality-specific encoders, our method directly incorporates structural information into visual tokens, mirroring successful tokenization strategies in text-only language models. We introduce a priority-guided encoding scheme that considers both frequency and spatial consistency, coupled with a multi-stage training procedure based on curriculum-driven data composition. These enhancements enable the transformer model to better capture cross-modal relationships and reason with visual information. Comprehensive experiments demonstrate improved performance across diverse vision-language tasks. By bridging the gap between visual and textual representations, our approach contributes to the advancement of more capable and efficient multimodal foundation models.
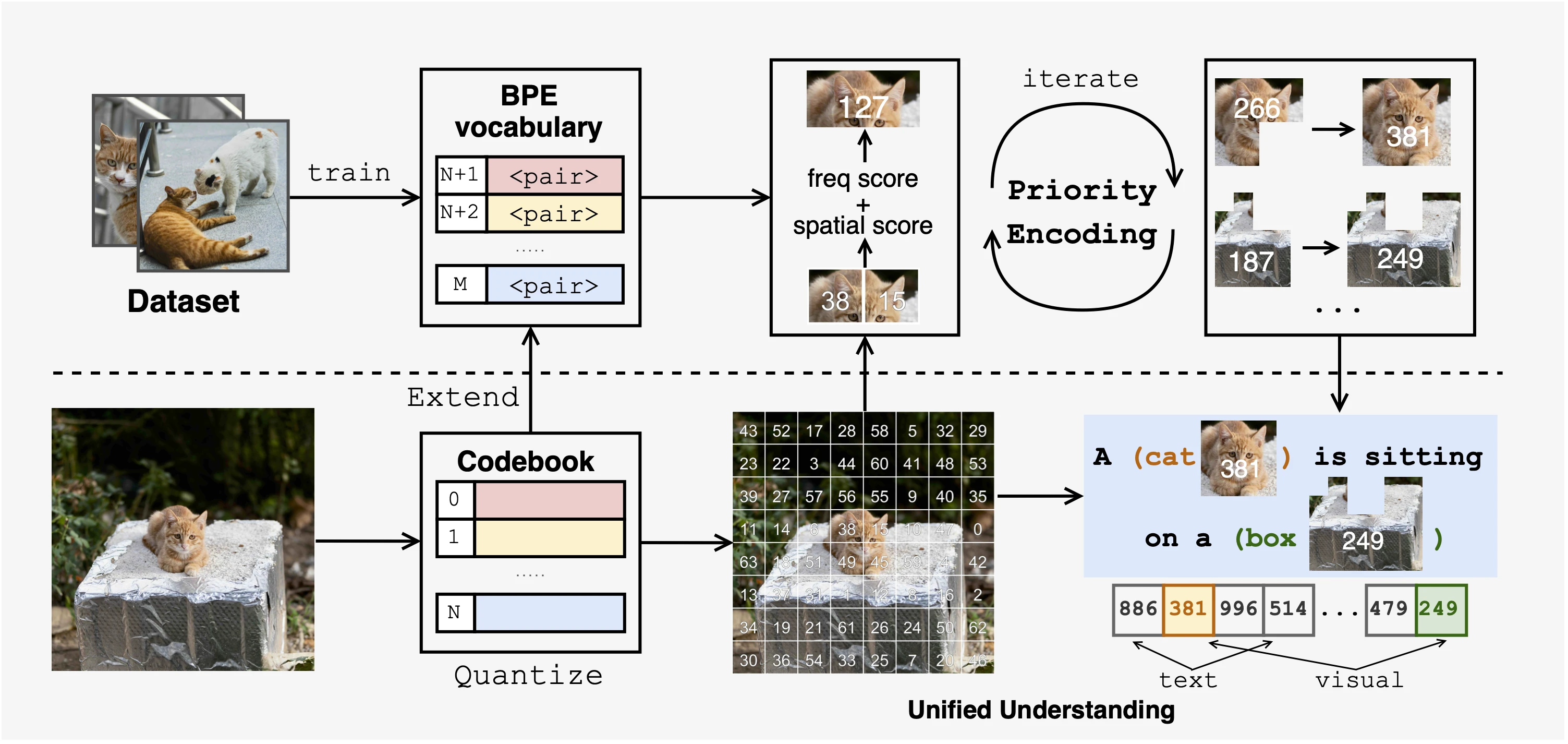
Priority-Guided Encoding

Based on the theoretical guidance from our previous paper, we designed a priority-guided encoding mechanism:
- Co-occurrence frequency: Statistics of the spatial adjacency of VQ tokens in the data.
- Spatial consistency: Evaluating which token pairs maintain stable spatial relationships across different images.
By integrating these two factors, our BPE tokenizer can combine frequently co-occurring and spatially consistent VQ tokens into new visual tokens, thereby encoding structured information about images at the token level. This design directly corresponds to our theoretical finding -- injecting structured priors through tokenization.
Model Expanding and Training
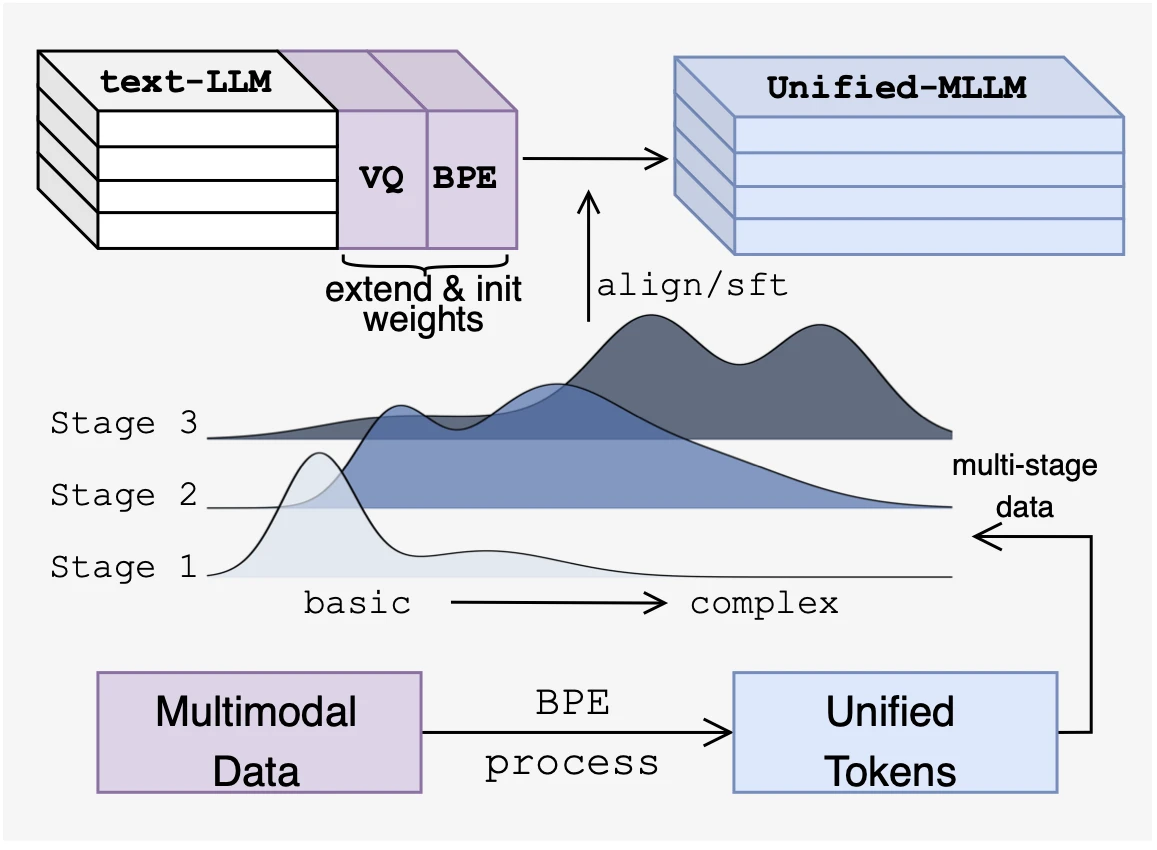
We first use VQ-GAN to quantize images into discrete token sequences. Unlike MLLMs that directly use these discrete visual tokens, we believe that these initial tokens only capture very local visual information and lack high-level semantic structure. This is precisely our motivation to further expand embeddings and adopt visual BPE tokens.
Visual BPE creates hierarchical representations, where encoded tokens progressively capture visual patterns from simple to complex. Based on this characteristic, we designed a matching learning curriculum: (1) Foundational Stage: Establish basic visual-language alignment; (2) Perceptual Stage: Learn detailed visual attributes; (3) Reasoning Stage: Develop complex visual reasoning capabilities; (4) Instruction Stage: Optimize task execution capabilities.
Experiments
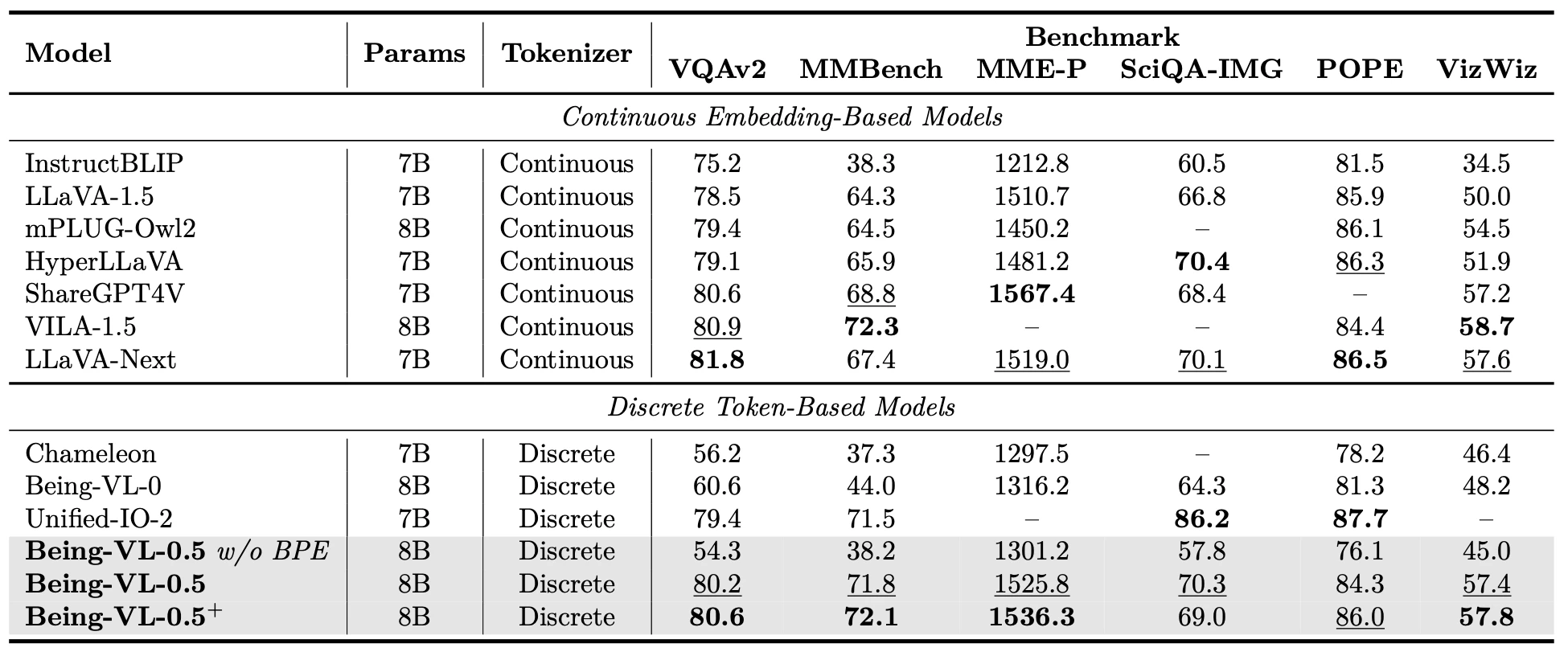
Our framework achieves competitive performance across multiple vision-language benchmarks, effectively narrowing the gap between discrete token-based and continuous embedding-based models, outperforming previous discrete token approaches while maintaining the advantages of unified token representation.

We conduct ablation studies to investigate the impact of the multi-stage training. The result shows that our standard approach achieves clear improvements over the single-stage training, demonstrating the effectiveness of the overall strategy.
Example Cases



Citation
@inproceedings{zhang2025beingvl05,
title={Unified Multimodal Understanding via Byte-Pair Visual Encoding},
author={Zhang, Wanpeng and Feng, Yicheng and Luo, Hao and Li, Yijiang and Yue, Zihao and Zheng, Sipeng and Lu, Zongqing},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year={2025}
}