


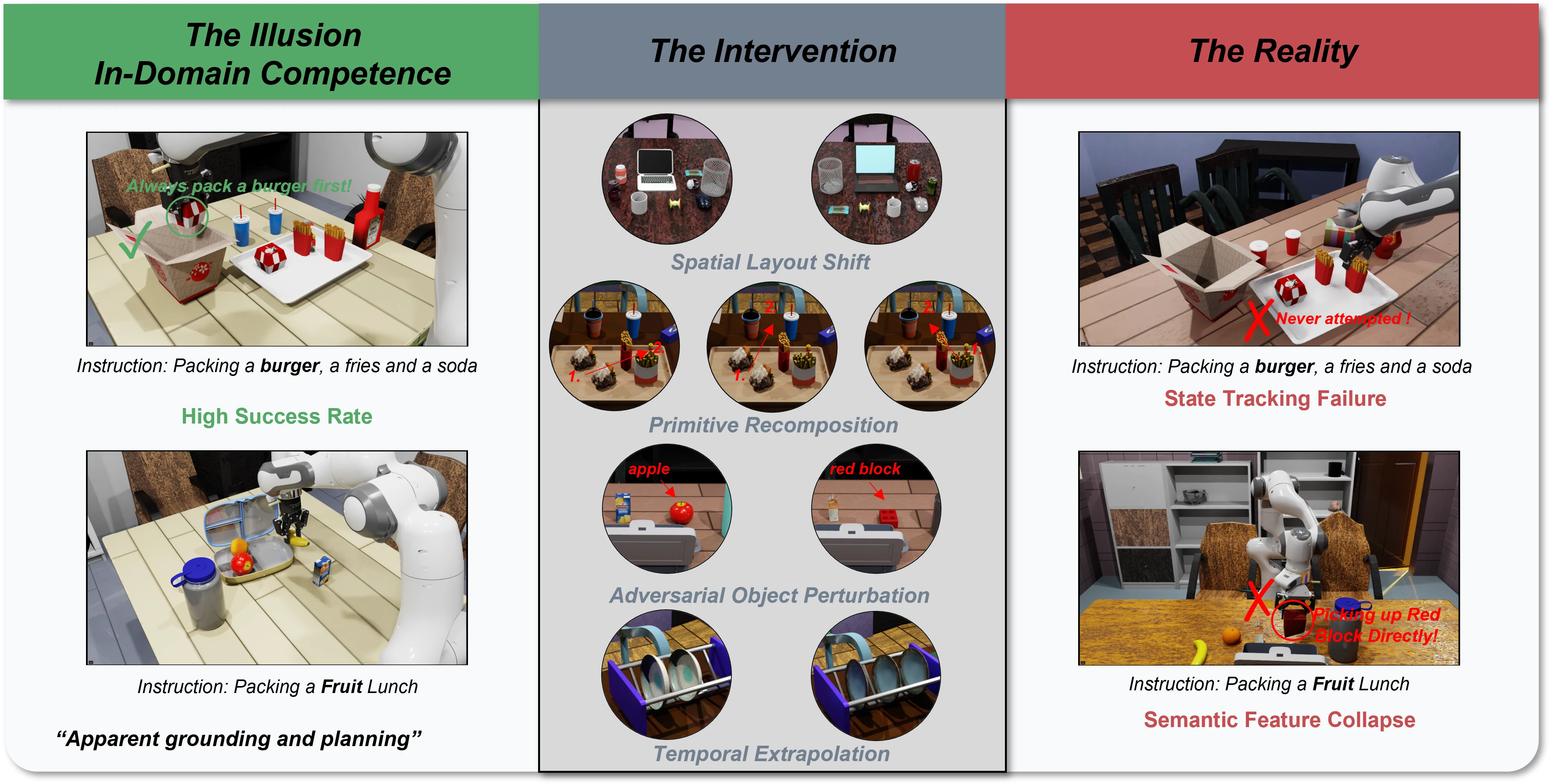
The Observation: The Illusion of Competence
Recent Vision-Language-Action (VLA) models report near-perfect success rates on standard robotic benchmarks. The narrative seems straightforward: scale up the parameters, pre-train on massive datasets, and general-purpose physical intelligence emerges.
In practice, however, these high scores often hide a systematic flaw. Existing evaluation protocols reward behavioral competence without validating the underlying reasoning. When a model successfully completes a task like "Packing a Fruit Lunch" by correctly picking up a red apple, it appears to possess genuine semantic understanding of the object. But what happens if you test that assumption?


When we subjected state-of-the-art models (including , GR00T-N1.6, and Being-H0.5) to these targeted visual interventions, their apparent competence collapsed.
The models were not actually reasoning about the environment. They had suffered from semantic feature collapse, relying on superficial visual heuristics--mapping a salient low-level feature (like the color red or a vague shape blob) directly to a memorized motor primitive, completely bypassing fine-grained semantic verification.
The Probe: Diagnosing True Embodied Reasoning
To systematically expose these shortcuts, we built BeTTER (Benchmark for Testing True Embodied Reasoning).
Unlike standard robustness benchmarks that merely add visual noise or change textures, BeTTER applies targeted causal interventions. Crucially, we enforce strict kinematic isolation: all objects are placed in known, reachable configurations. If a model fails our probe, it is not because it lacks the low-level motor skills to reach the target, but because its high-level reasoning has broken down.
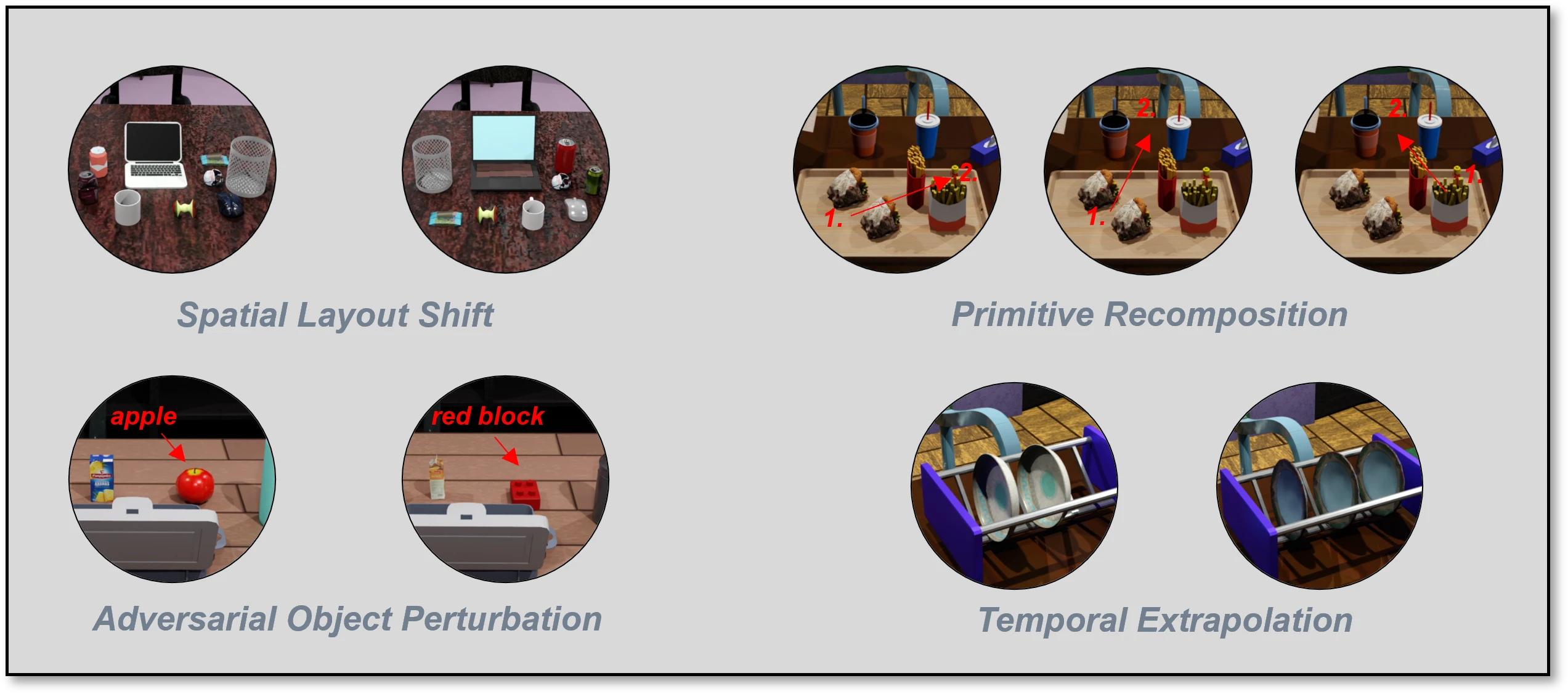
We stress-test models across four distinct cognitive dimensions:
- Spatial Layout Shift: Rearranging objects or altering spatial relationships with distractors to expose visual-layout biases.
- Primitive Recomposition: Recombining learned action primitives (e.g., evaluating sequence after only training on and ) to test compositional generalization.
- Adversarial Object Perturbation: Replacing targets with visually similar but semantically distinct objects to examine fine-grained semantic grounding.
- Temporal Extrapolation: Extending task horizons or modifying initial states to evaluate causal state tracking versus visual memorization.
The Reality of Cognitive Breakdowns
Under the BeTTER probe, the illusion of reasoning breaks down into predictable, systematic failure modes:



Where Does the Reasoning Go?
This leads to a fundamental paradox: these VLAs are initialized from powerful Vision-Language Models (VLMs) that already possess strong reasoning capabilities. So where does that reasoning--which we denote as the high-level semantic representation --go during continuous physical control?
We traced the representational degradation step-by-step through the VLM-to-VLA adaptation pipeline.
| Model / Configuration | EmbSp. | RefSpatial | EgoPlan-Bench2 |
|---|---|---|---|
| Reference: Gemini-2.5-Pro | 78.74 | 38.16 | 42.85 |
| Reference: Mimo-Embodied (7B) | 76.24 | 48.00 | 43.00 |
| Reference: RoboBrain-2.0 (7B) | 76.32 | 32.50 | 33.23 |
| Reference: RoboBrain-2.0 (32B) | 78.57 | 54.00 | 57.23 |
| Stage 1: Capacity Scaling | |||
| 8B Base | 74.96 | 27.50 | 40.80 |
| 4B Base | 72.08 | 23.00 | 36.83 |
| 2B Base | 60.19 | 6.00 | 33.38 |
| Stage 2: The Pre-training Shift | |||
| 2B + VLM + VLA Data (Multi-patch) | 57.47 | 29.50 | 31.95 |
| Stage 3: The "Myopic" Constraint | |||
| 2B + VLM + VLA Data (Single 224px) | 52.42 | 7.50 | 31.95 |
The steep drop in Spatial Grounding (RefSpatial) and Sequential Planning (EgoPlan) as the model undergoes: 1) Capacity Scaling 8B -> 2B, 2) Co-training, and 3) Perceptual Downsampling.
- Capacity Compression: Scaling down from 8B to 2B parameters for onboard compute strict limits the model's representational bandwidth, crippling its ability to sustain rich causal-relational reasoning.
- The "Myopic" Perceptual Constraint: Real-time control demands high-frequency inference, forcing models to heavily downsample multi-patch visual inputs to a single low-resolution image (e.g., 224x224). This structural bottleneck literally erases the fine-grained semantics necessary for robust embodied reasoning.
- Shortcut Optimization: During fine-tuning, the optimization process naturally favors pathways that minimize immediate action-prediction loss. With semantic capacity choked, the model trades away reasoning () and overfits entirely to its sensorimotor and kinematic priors ().
Highly static evaluation environments mask this degradation, allowing models to max out success rates through spatial overfitting. But under distribution shifts, this brittle trajectory memorization catastrophically fails.
The Benchmark Paradox: Validating the Shortcut
To empirically validate how standard benchmarks mask this degradation, we evaluated different pre-training recipes alongside established state-of-the-art models. We compared performance across two distinct regimes: the highly static LIBERO benchmark (in-distribution) and the challenging CALVIN benchmark (out-of-distribution).
| Configuration | LIBERO (Static / In-Distribution) Average Success | CALVIN (OOD / ABC → D) Average Length ↑ |
|---|---|---|
| Reference: GR00T-N1.6 | 96.99% | 4.244 |
| Reference: | 96.85% | 4.126 |
| Reference: Being-H0.5 | 98.90% | 4.138 |
| Ours: No Pre-training | 97.40% | 3.669 |
| Ours: VLA (OXE Only) | 96.25% | 3.860 |
| Ours: VLA + VLM | 97.20% | 4.086 |
The stark contrast: on LIBERO, all configurations look equally perfect. On CALVIN, the truth is revealed.
The results clearly resolve the paradox. In visually consistent, fixed-camera environments like LIBERO, tasks can be "solved" almost entirely through kinematic heuristics (). The benchmark cannot distinguish true semantic reasoning from trajectory memorization. However, under CALVIN's out-of-distribution splits--where environmental shifts invalidate memorized spatial heuristics--genuine semantic grounding () becomes the strictly required pathway for success.
Real-World Evidence: Closing the Sim-to-Real Loop
To confirm these representational bottlenecks are not simulation artifacts, we conducted targeted physical stress tests on the SO101 robotic platform.

To disentangle cognitive reasoning from simple kinematic execution, we evaluated the policy using diagnostic matrices. We systematically varied the presence and location of targets and distractors, revealing a stark contrast between short-horizon heuristics and long-horizon breakdowns.
1. The Short-Horizon Illusion
In short-horizon tasks (e.g., "Put the lemon into the fruit basket"), the policy exhibits strong apparent competence. As shown below, it correctly grasps the target (Row 1) and properly terminates if the target is already placed (Row 2).
| Distractor → Target ↓ | On Table | In Basket | Absent |
|---|---|---|---|
| On Table | ✅ Success (Grasps Lemon) | ✅ Success (Grasps Lemon) | ✅ Success (Grasps Lemon) |
| In Basket | ✅ Correct Freeze (Done) | ✅ Correct Freeze (Done) | ✅ Correct Freeze (Done) |
| Absent | ❓ Ambiguous (Grasps Distractor) | ❓ Ambiguous (Freezes / Air Grasp) | ❓ Ambiguous (Air Grasp) |
However, this success is an illusion. The limited execution horizon allows policies to succeed via simple reactive heuristics (e.g., mapping a yellow blob directly to a grasp primitive) without requiring actual causal state tracking.
2. Deconstructing Long-Horizon Breakdowns
To unmask the limitations of reactive control, we extend the evaluation to long-horizon tasks (e.g., "Put all the fruits into the fruit basket"). By deliberately disrupting the expected execution chain, we force the model to either plan causally or fail.
| Mangosteen (Target 2) → Lemon (Target 1) ↓ | On Table | In Basket | Absent |
|---|---|---|---|
| On Table | ✅ Success (Packs Both) | ✅ Success (Packs L, Ends) | ❌ Behavioral Inertia (Packs L → Air Grasp) |
| In Basket | ❌ Phase Conflict (Freezes/Skips L) | ✅ Success (Recognizes Done) | ❌ Phase Conflict (Oscillates/Air Grasp) |
| Absent | ✅ Success (Packs M) | ✅ Correct Freeze (Done) | ❓ Ambiguous (Air Grasp) |
Without genuine semantic representation, the policy defaults to rigid proprioceptive assumptions, leading to two massive failure modes (highlighted above):
- Behavioral Inertia (Proprioceptive Overfitting): When the first target is present but the second is missing, the model successfully packs the first, but then blindly executes a perfect "air grasp" at the exact spatial coordinates where the second target usually sits. It trusts its memorized trajectory over the actual visual scene.
- Phase Conflict (Temporal Disorientation): When the first target is pre-placed in the basket, the visual observation (Step 1 completed) conflicts with the robot's proprioceptive state (). The model fails to track the causal state, resulting in near-zero velocity outputs (freezing) or erratic exploratory motions.
These physical diagnostics provide mechanistic closure: the reasoning deficits observed in VLAs are not sim-to-real gaps. They are fundamental consequences of treating cognitive reasoning as a byproduct of trajectory memorization.
Wrapping Up
The findings from the BeTTER benchmark unmask the "illusion of embodied reasoning" in state-of-the-art VLAs. While current models achieve impressive success rates on highly static evaluation environments, this performance often masks shortcut learning. When evaluated under controlled causal interventions, policies consistently regress to brittle trajectory memorization and superficial heuristics.
Our mechanistic analysis traces these vulnerabilities directly to structural architectural bottlenecks. Requirements like capacity compression and myopic perceptual downsampling systematically degrade a model's foundational semantic representation. Consequently, optimization defaults to overfitting to the sensorimotor representation ().
Open-world generalization strictly requires genuine semantic grounding. To move from superficial behavioral competence to genuine physical intelligence, future VLA paradigms must explicitly resolve the structural tension between the demands of high-frequency continuous control and the preservation of high-level cognitive reasoning.
Citation
If you find our benchmark or insights useful in your research, please consider citing:
@article{xu2026unmasking,
title={Unmasking the Illusion of Embodied Reasoning in Vision-Language-Action Models},
author={Xu, Haiweng and Zheng, Sipeng and Luo, Hao and Zhang, Wanpeng and Xi, Ziheng and Lu, Zongqing},
journal={arXiv preprint arXiv:2604.18000},
year={2026}
}