

We present DemoFunGrasp, a sim-to-real framework for universal dexterous functional grasping via demonstration editing reinforcement learning.
Key Concept
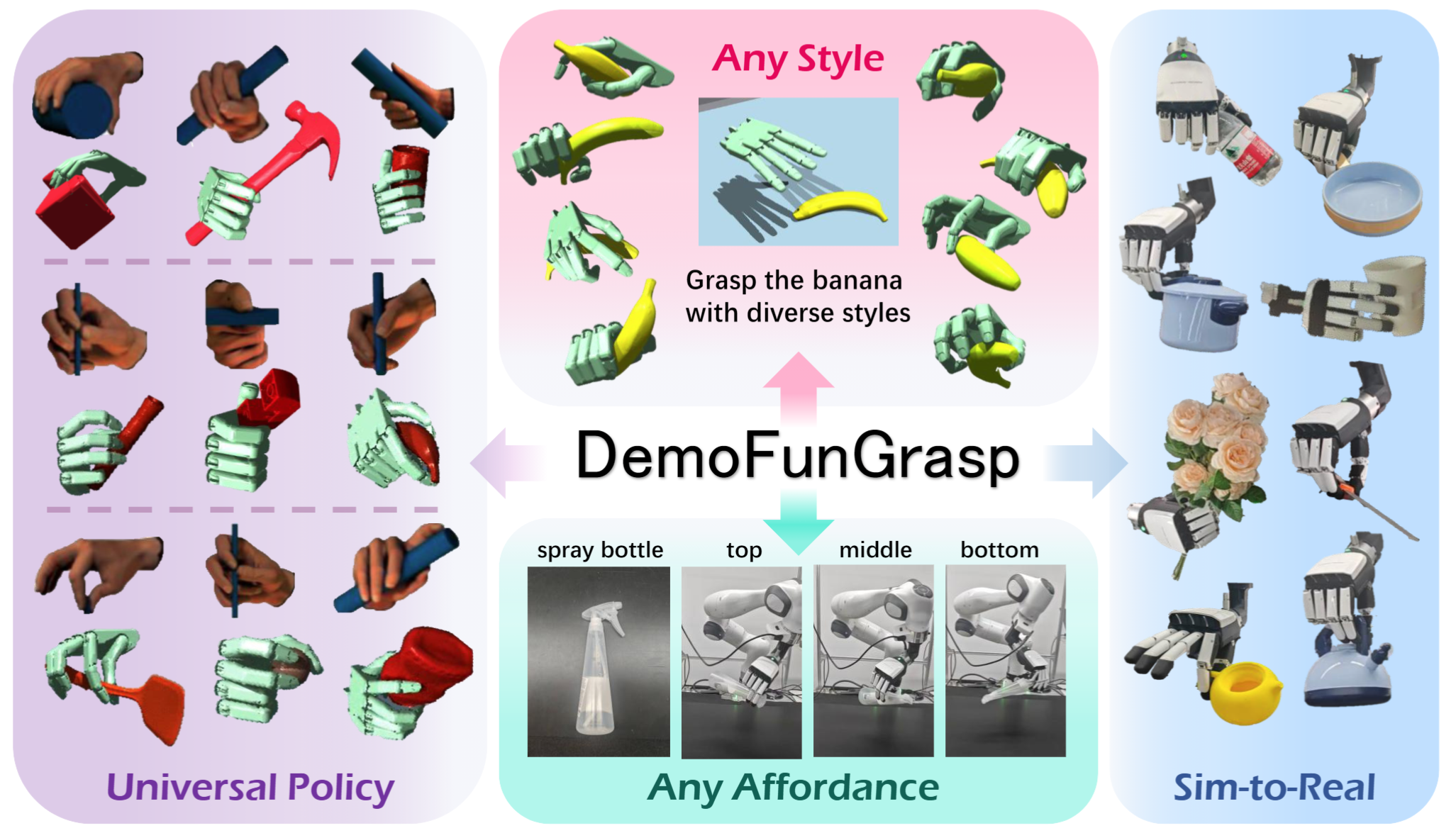
DemoFunGrasp enables affordance-centric grasping, supporting arbitrary grasp poses conditioned on arbitrary affordance regions across diverse objects. It generalizes to unseen object–affordance–style combinations with zero-shot sim-to-real transfer. During real-world deployment, a Vision–Language Model (VLM) can be used for autonomous planning and execution.
Real-World Demo
Dish soap bottle
Bouquet
Pan
Toolbox
Kettle
Yellow Teapot
Rasp
Brown Teapot
Wooden Holder
Saucepan
Watering Pitcher
Bowl
Small Bucket
Hand Sanitizer Bottle
Spray Bottle
Pipeline
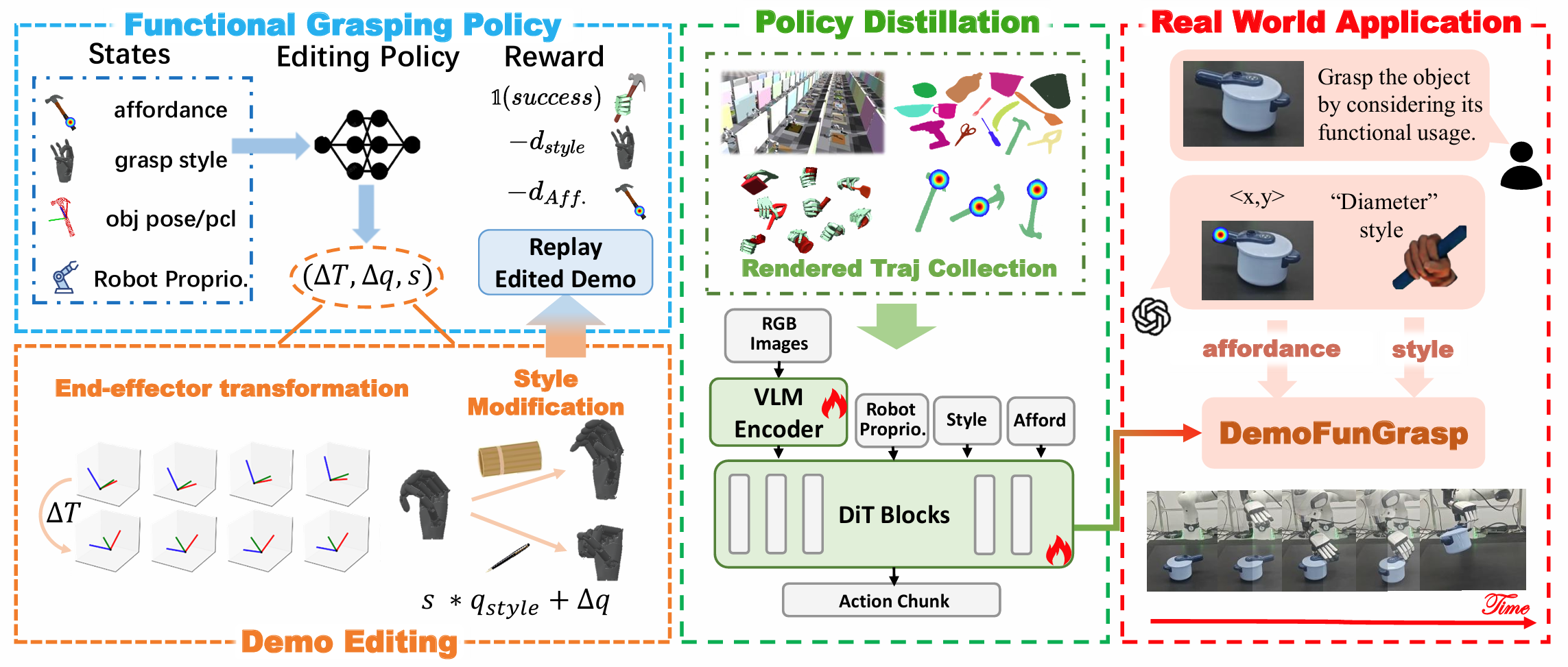
The framework consists of four components:
- Demonstration editing: Adapt a source demonstration using end-effector transformation and object-geometry–aware hand-style adjustment.
- Functional grasping policy learning: Train a single-step reinforcement learning policy conditioned on both affordance cues and grasp style specifications.
- Vision-based imitation: Transfer the learned policy to RGB observations for closed-loop, vision-based execution.
- Real-world deployment: Use a VLM for autonomous planning and execution.
Experiment

Our experiments evaluate simulation and real-world performance under human-annotated and VLM-predicted grasping conditions. DemoFunGrasp generalizes effectively to unseen object–affordance–style combinations and attains high success rates (GSR), affordance accuracy (IAS), and style adherence (ISS). Integrated with a VLM for instruction-following, the system reaches strong real-world performance.
Citation
@inproceedings{mao2026universal,
title={Universal Dexterous Functional Grasping via Demonstration-Editing Reinforcement Learning},
author={Chuan Mao and Haoqi Yuan and Ziye Huang and Chaoyi Xu and Kai Ma and Zongqing Lu},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}