


Overview
Recent work has shown that human manipulation data is a valuable complement to robot data for VLA pretraining, offering richer behavioral coverage and a more scalable source of action experience. However, human data is not always original with action signals. Lab-collected datasets provide precise hand-motion supervision and dense task annotations, but are typically limited to controlled environments and narrower interaction diversity. By contrast, in-the-wild human videos capture broader behaviors and richer contextual variation, but usually lack reliable motion labels. The core challenge, therefore, is not simply to use human videos, but to combine these two complementary forms of human data in a way that preserves both action fidelity and scale.
JALA is designed around exactly this trade-off, combining a lab-annotated subset with native hand-motion supervision and a larger in-the-wild subset of instruction-video pairs. This setup allows JALA to benefit from the strengths of both sources: the lab subset supplies accurate action grounding, while the in-the-wild subset contributes diversity, contextual richness, and scale. The question JALA addresses is how to turn this heterogeneous human data mixture, especially the unlabeled portion, into a unified source of action-centric supervision for VLA pretraining.
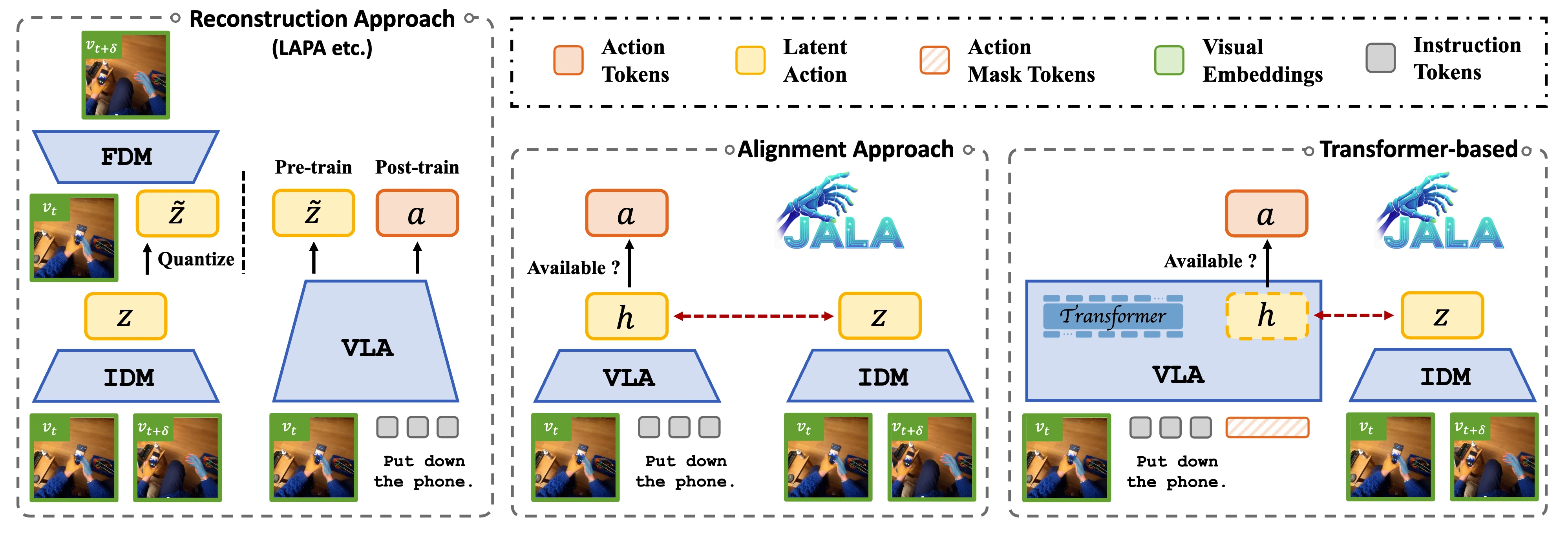
From Reconstruction to Joint Alignment
A common strategy for leveraging non-action videos is learn to infer latent actions through a reconstruction-driven forward dynamics model. In this paradigm, an inverse dynamics model first maps visual transitions to latent actions, and a forward dynamics model then reconstructs future frames to constrain those latent actions to remain action-relevant. While this formulation is reasonable in controlled settings, it becomes much less desirable for fine-grained human manipulation in the wild. When appearance, background texture, occlusion, and camera motion vary substantially, reconstruction objectives can push the model toward modeling visual detail rather than the underlying action itself. JALA takes a different route: instead of learning latent actions through reconstruction, it learns them through joint alignment with action-relevant embeddings. The emphasis is shifted away from how the scene should look, and toward a direct bond to the action.
Why Joint Alignment Captures Behavior Dynamics
The key to JALA is that the two signals being aligned are both intrinsically action-related. On one side, JALA uses a predictive embedding extracted from the Transformer VLA during masked chunk prediction. Because the hidden states are trained to recover masked motion tokens jointly within a chunk, they naturally encode chunk-level movement patterns in context. On the other side, JALA uses a latent action inferred from chunk boundary frames by the Latent Action Perceiver, which captures the transition dynamics that actually occurred in the video. Individually, neither signal is sufficient: motion prediction alone lacks explicit visual dynamics, while inverse dynamics alone does not guarantee action-centric representations. By aligning them, JALA fuses predicted motion structure with observed visual transition, constraining the latent space around behavior dynamics rather than appearance.
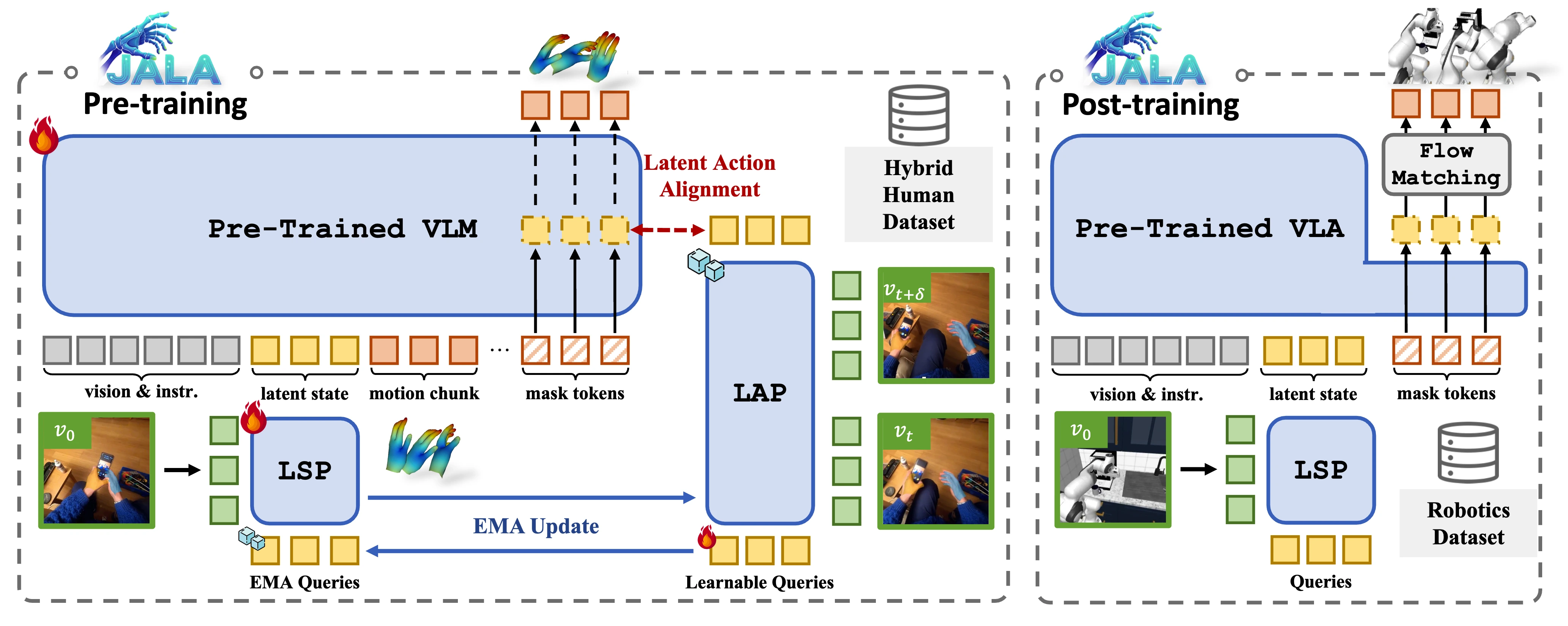
Architecture
JALA is built on a Transformer-based VLA that processes visual tokens, instruction tokens, and motion tokens jointly. During pretraining, hidden states from masked motion chunks are taken as predictive embeddings, while the Latent Action Perceiver (LAP) maps chunk boundary frames into the latent action space and provides supervision even when motion labels are absent. To stabilize alignment between heterogeneous signals, JALA further introduces a parameter-shared Latent State Perceiver (LSP) and a decoupled asymmetric EMA update between LAP and LSP. For samples with native hand-motion annotations, action supervision is added to further anchor the shared space to explicit control semantics. After pretraining, the learned predictive embeddings are transferred into a flow-matching head for downstream robot control.
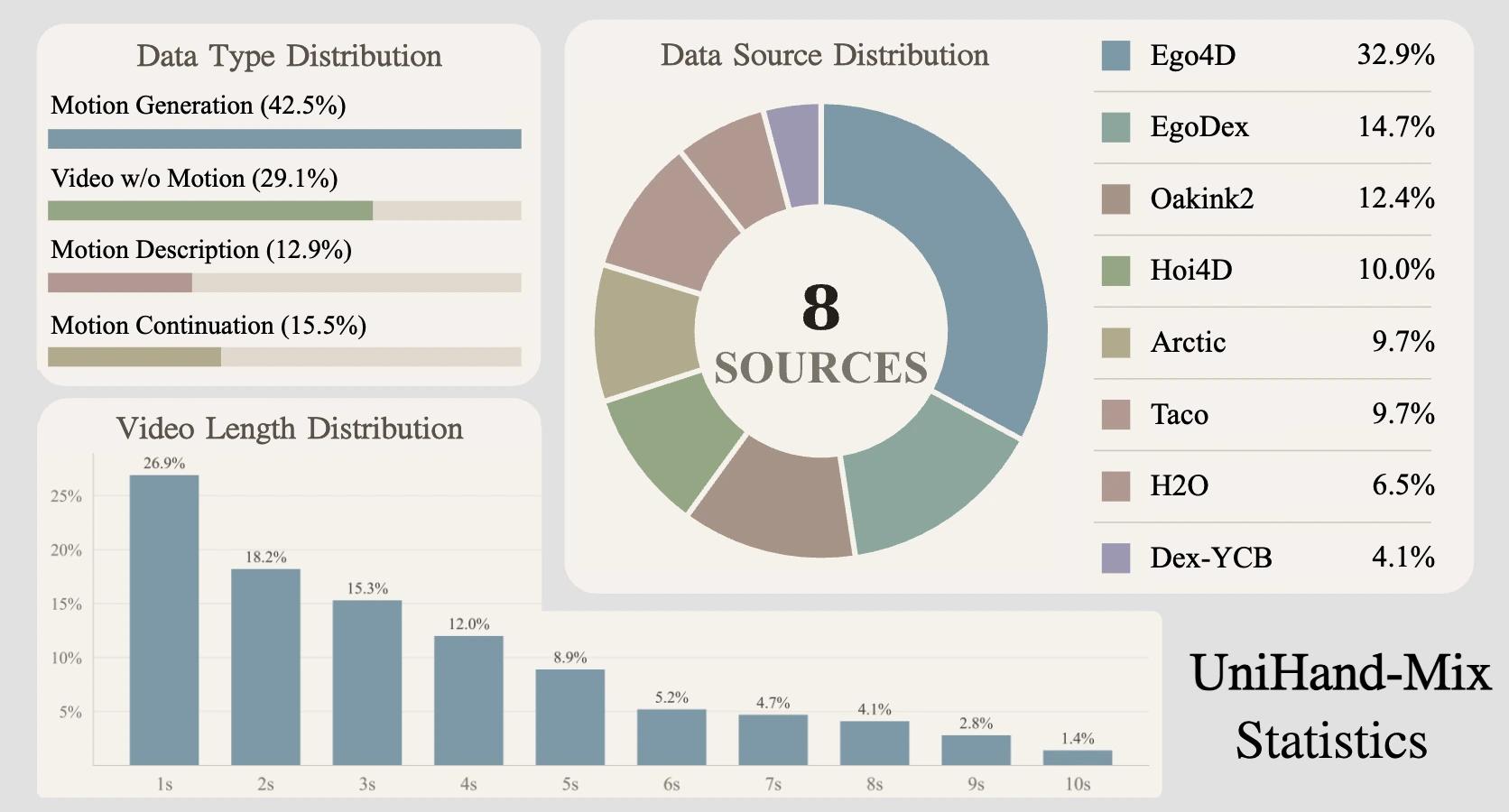
UniHand-Mix
To support this training setup, we build UniHand-Mix, a hybrid human manipulation dataset that unifies high-quality lab-collected videos with diverse in-the-wild egocentric videos. The lab subset provides precise MANO-based hand motion sequences together with dense task descriptions, while the in-the-wild subset is curated from Ego4D through hand visibility filtering, hand-centric activity validation, and optional pseudo hand-pose estimation. In total, UniHand-Mix contains over 7.5 million instruction-video samples, including 5 million+ lab-annotated instruction-video-motion samples and 2.5 million in-the-wild instruction-video pairs, creating a unified pretraining source with both action fidelity and behavioral diversity.
Real-World Demo
Experiments
We evaluate JALA from three complementary perspectives. In hand motion generation, JALA generates coherent, temporally consistent, well-aligned hand motion across both lab-collected and in-the-wild scenes. In simulation benchmarks, including LIBERO, RoboCasa, and GR1, JALA consistently outperforms reconstruction-based latent action baselines and remains strong across domain shift, few-shot transfer, and embodiment variation. In real-world robot experiments, JALA also transfers more reliably, showing stronger robustness under visual variation and more stable behavior in multi-step manipulation.

Discussion
Overall, JALA shows that unlabeled human videos can serve as effective action-centric supervision without relying on pixel reconstruction. By aligning predictive motion structure with visual transition dynamics, JALA turns heterogeneous human data into a unified pretraining signal that scales well and transfers effectively to downstream robot control.
Citation
@inproceedings{luo2026jointalignedlatentaction,
title={Joint-Aligned Latent Action: Towards Scalable VLA Pretraining in the Wild},
author={Hao Luo and Ye Wang and Wanpeng Zhang and Haoqi Yuan and Yicheng Feng and Haiweng Xu and Sipeng Zheng and Zongqing Lu},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}