

Text-to-motion (T2M) generation aims to create realistic human movements from text descriptions, with promising applications in animation and robotics. Despite recent progress, current T2M models still perform poorly on unseen text descriptions because existing motion datasets remain limited in scale and diversity. OpenT2M addresses this problem with a million-level, high-quality, open-source motion dataset containing over 2800 hours of human motion, together with MonoFrill, a pretrained motion model designed to achieve strong T2M results without complicated designs or technique tricks as "frills".
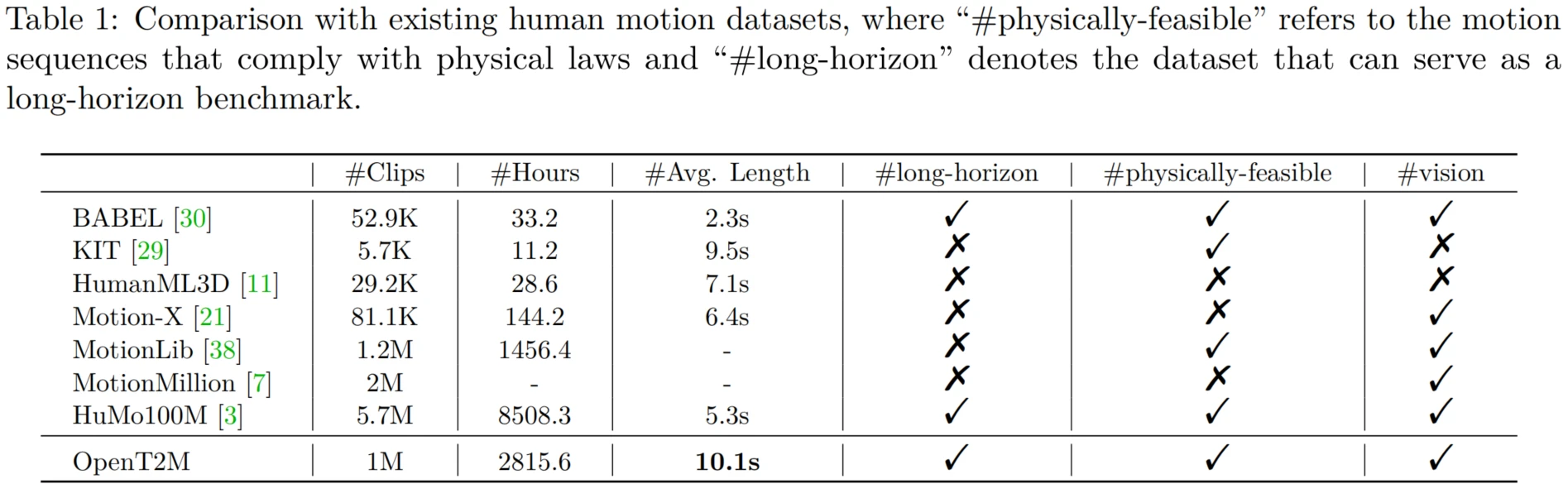
OpenT2M Dataset
OpenT2M offers four key improvements over existing datasets. (1) Physically feasible validation: all motion sequences are validated to be physically feasible and simulatable, making them suitable for training models that can control humanoid robots. (2) Multi-granularity quality filtering: sequences with occlusions or partial body captures are removed so that the full human body remains visible throughout each motion sequence. (3) Second-wise descriptions: detailed text labels are generated for each second of motion and then combined into a comprehensive sequence-level description. (4) Long-horizon motions: an automated pipeline is used to create extended motion sequences for complex, long-horizon generation.
Each sequence in OpenT2M undergoes rigorous quality control through physical feasibility validation and multi-granularity filtering, with detailed second-wise text annotations. This combination is meant to support both realistic motion generation and stronger generalization to more complex descriptions.
Sample Clips from the Dataset
The released materials also show how OpenT2M covers diverse motion types. The clips below are short examples from the dataset, each paired with second-wise descriptions that can be merged into a fuller instruction.
MonoFrill Model
MonoFrill uses a motion tokenizer to discretize sequences into tokens, which are then generated autoregressively by an LLM. To integrate motion tokens into the LLM backbone, the model expands the vocabulary with K discrete motion codes. The name "MonoFrill" emphasizes a simple and extendable design without complicated components. Its core component is 2D-PRQ, a motion tokenizer that captures spatiotemporal dependencies by decomposing the body into parts. The sequence is conceptualized as a 2D image, with time as the width and body parts as the height. This makes it possible to use a 2D convolution block for motion encoding, capturing both temporal correlations across frames and spatial dependencies between different body parts.
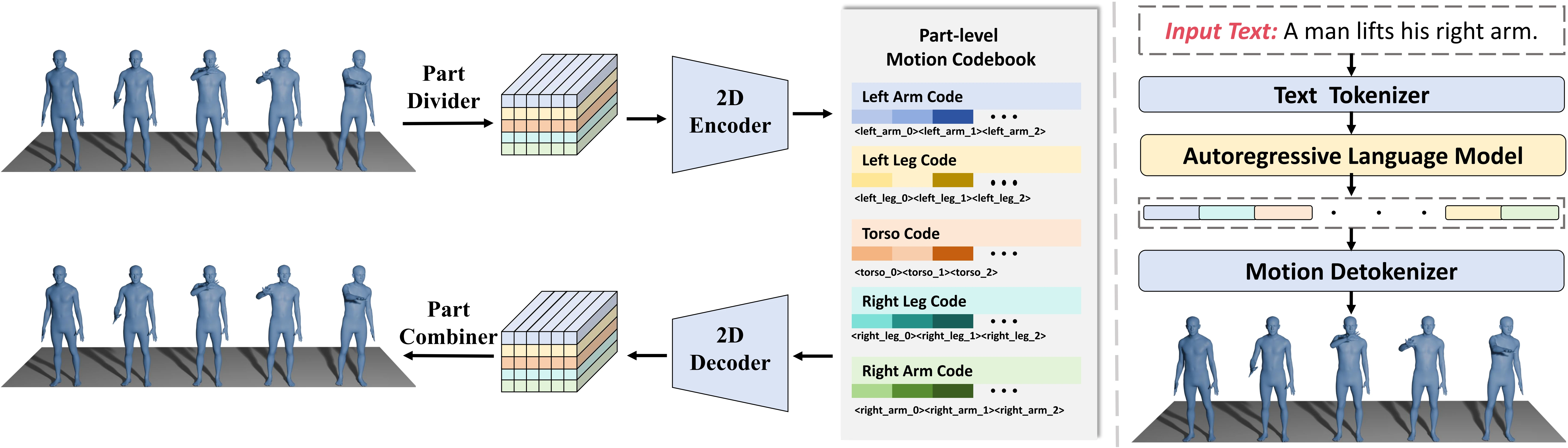
This design is intended to maintain whole-body coordination and consistency while keeping the model architecture relatively simple.
Experiments
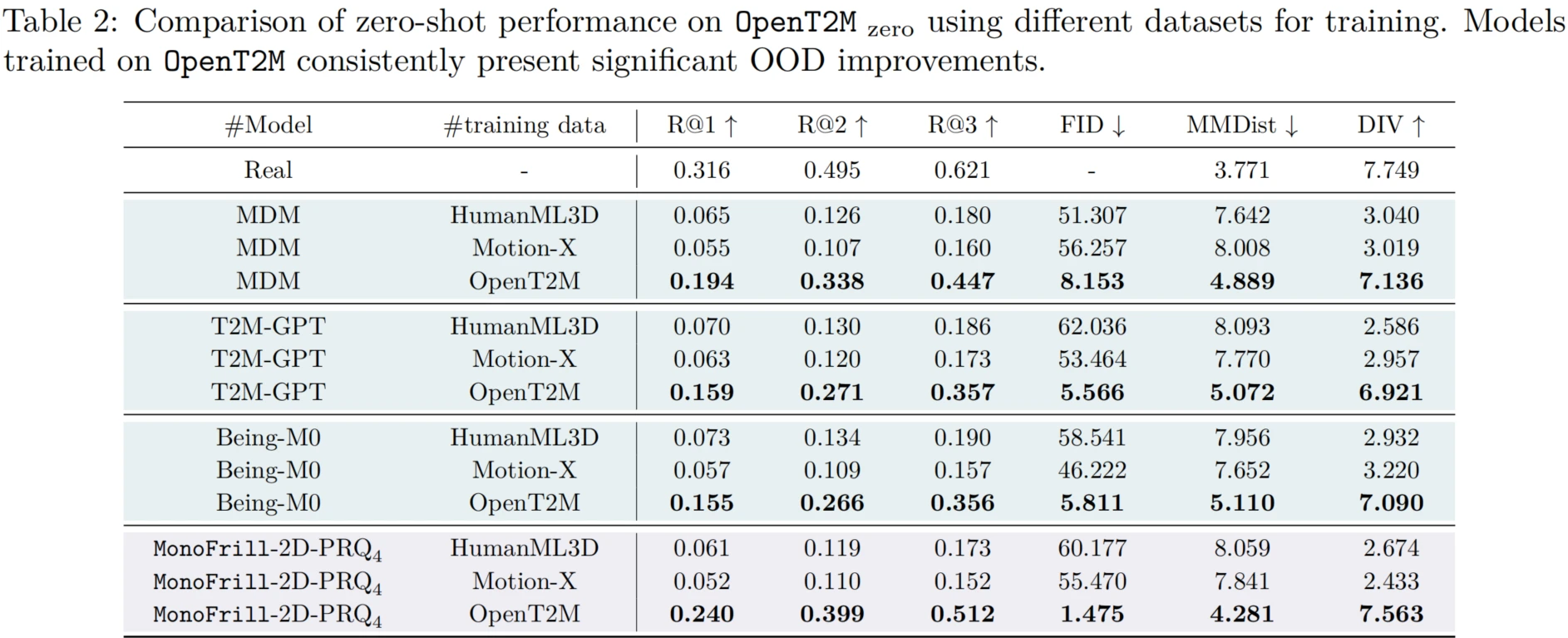
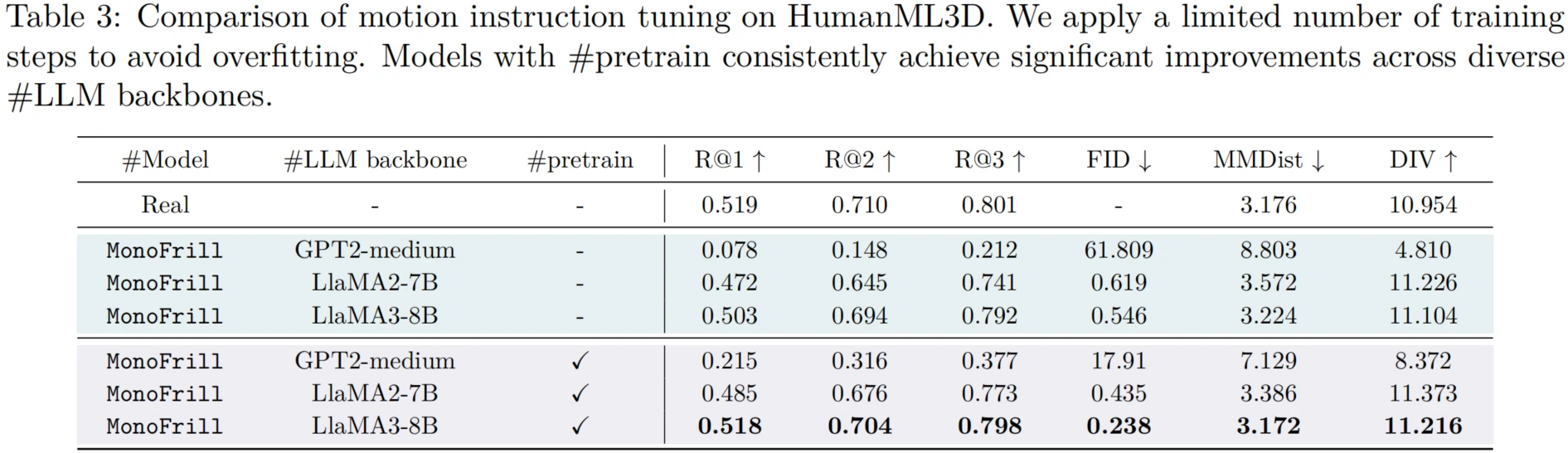
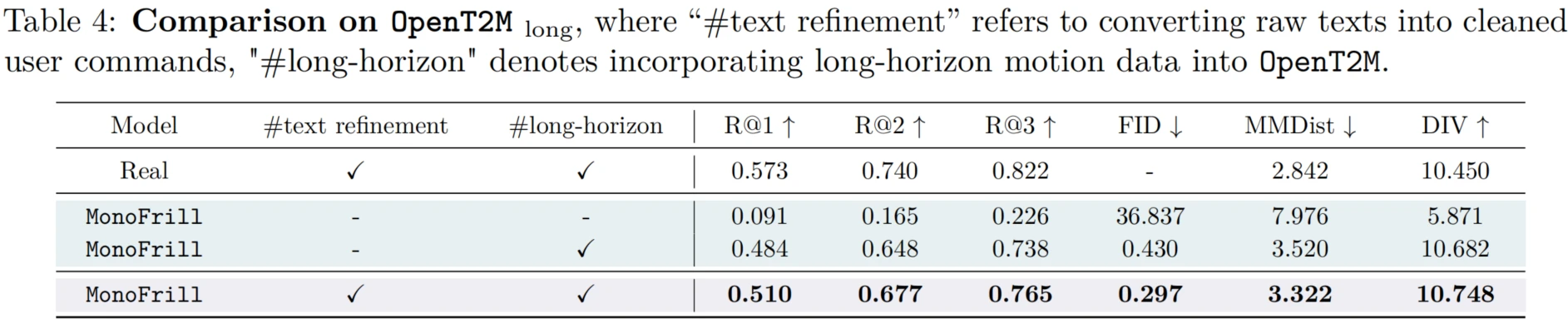
To validate the effectiveness of OpenT2M, the paper focuses on three aspects of T2M evaluation: 1) Zero-shot generalization to out-of-domain cases. 2) Adaptation to novel motion activities through instruction tuning. 3) Long-horizon motion generation.
Experiments show that OpenT2M significantly improves the generalization of existing T2M models. Building on this dataset, MonoFrill achieves compelling results with a simple design, while 2D-PRQ provides stronger motion reconstruction and zero-shot performance.
Effectiveness of 2D-PRQ
2D-PRQ outperforms previous tokenization methods, including PRQ, on large-scale datasets. Under a consistent configuration, it achieves substantially lower reconstruction error on Motion-X and OpenT2M while using a simpler architecture. The main advantage comes from its 2D convolutional design, which jointly models spatial and temporal dependencies.
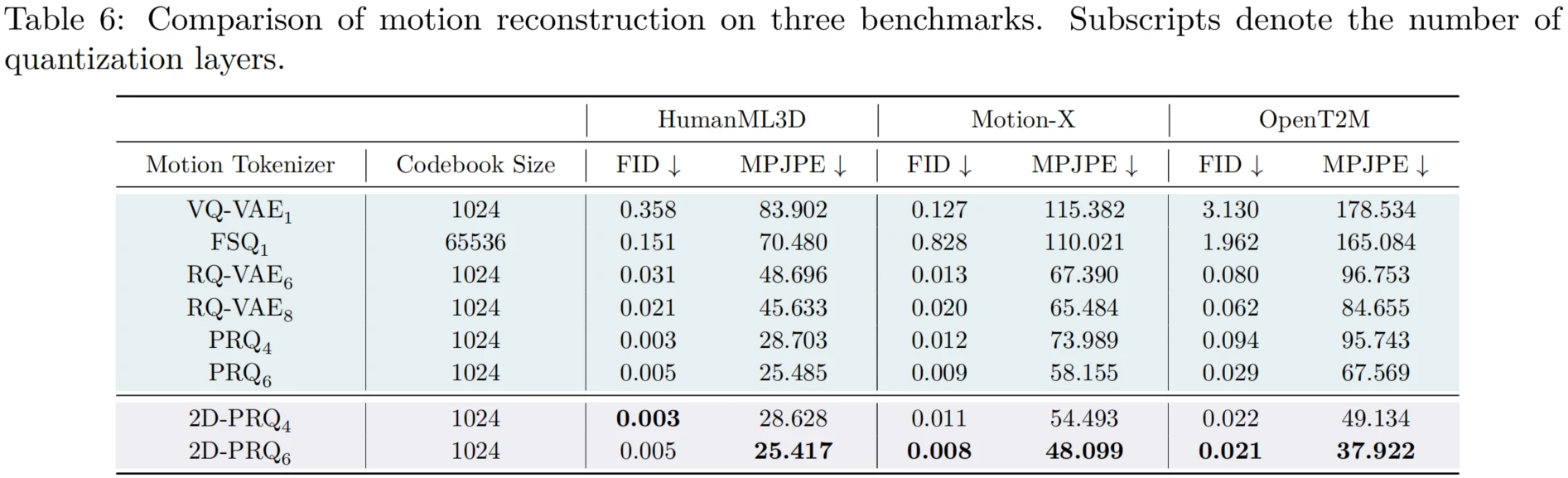
Overall, OpenT2M and MonoFrill aim to advance the T2M field by addressing longstanding challenges in data quality, benchmark construction, and generalization.
Citation
@inproceedings{cao2026opent2m,
title={OpenT2M: No-frill Motion Generation with Open-source, Large-scale, High-quality Data},
author={Bin Cao and Sipeng Zheng and Hao Luo and Boyuan Li and Jing Liu and Zongqing Lu},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}