

Robot post-training sounds straightforward: collect more demonstrations, mix in data from more robots, fine-tune. In practice, the checkpoint often gets worse. We pooled demonstrations from three very different platforms into one generalist training run and watched real-robot success rate drop by over 10 percentage points compared to per-robot training. The data was not bad. It was just uneven, and standard post-training had no way to tell which demonstrations actually deserved emphasis.
The Observation
The idea behind Posterior-Transition Reweighting (PTR) came from a simple observation about what offline robot data already contains. Every recorded action comes paired with something extra: the observation that followed it, i.e. what actually happened after the robot moved.
Think about what this means for data quality. When a demonstration is clean and the action is well-suited to the current context, the post-action observation should be a natural, predictable consequence of that action. A good grasp leads to a distinctive lift; a precise wipe leads to a visibly cleaner board. But when the action comes from hesitation, recovery, or a mismatched embodiment, the link between action and consequence becomes blurry. The future observation could have come from many different actions, and there is nothing distinctive about the pairing.
This gives us a way to score training samples without any reward labels: check whether the post-action consequence is identifiable given the current context and the action. If it is, the sample is informative and should receive more emphasis. If not, the sample is ambiguous and should stay at baseline weight or below.
PTR turns this into a concrete test. For each training sample, we encode the post-action observation as a latent target, drop it into a pool of mismatched alternatives from other samples, and ask: can a lightweight scorer pick out which future actually followed this action? Samples where the scorer succeeds get upweighted. Samples where the scorer cannot tell the matched future apart from random alternatives fall back to standard weighting. Samples where the matched future is even less likely than the pool average get suppressed.
The policy stack stays intact. PTR adds a compact side pathway: a BeliefTokenizer that summarizes interaction history into a few proxy tokens, an EMA target encoder for post-action observations, and a transition scorer that runs the identification test. All of this trains jointly with the action head in a single forward-backward pass.
How the Score Works
The identification test produces a posterior over candidate targets. The PTR score measures how much this posterior concentrates on the correct match compared to a uniform guess:
When , the matched future stands out, meaning the action was informative. When , the scorer cannot distinguish the real future from alternatives, so the sample reverts to uniform weighting. When , the matched future is less likely than the pool average, and the sample gets down-weighted.
This score is then mapped to a conservative weight through exponentiation, clipping, and a mixture with uniform:
The clipping bounds guarantee that no single sample can dominate the gradient update, and the mixture coefficient controls how far the induced training distribution can drift from the original data. When , PTR reduces to standard supervised post-training. This is what makes PTR "conservative": the reweighting is bounded by construction, with a formal KL divergence guarantee between the induced and original distributions.
Theoretically, the PTR score has a clean interpretation: in the large-candidate limit, it converges to the KL divergence between the action-conditioned consequence distribution and the baseline pool distribution. Informative actions produce distinctive futures that stand out; ambiguous actions blur this distinction. The details are in Section 4.3 of the paper.
Resilience to Noisy Data
Before looking at real robots, we stress-tested PTR on simulation benchmarks with deliberately corrupted training data: Gaussian noise injected into actions, randomly truncated trajectories, and shuffled language instructions.
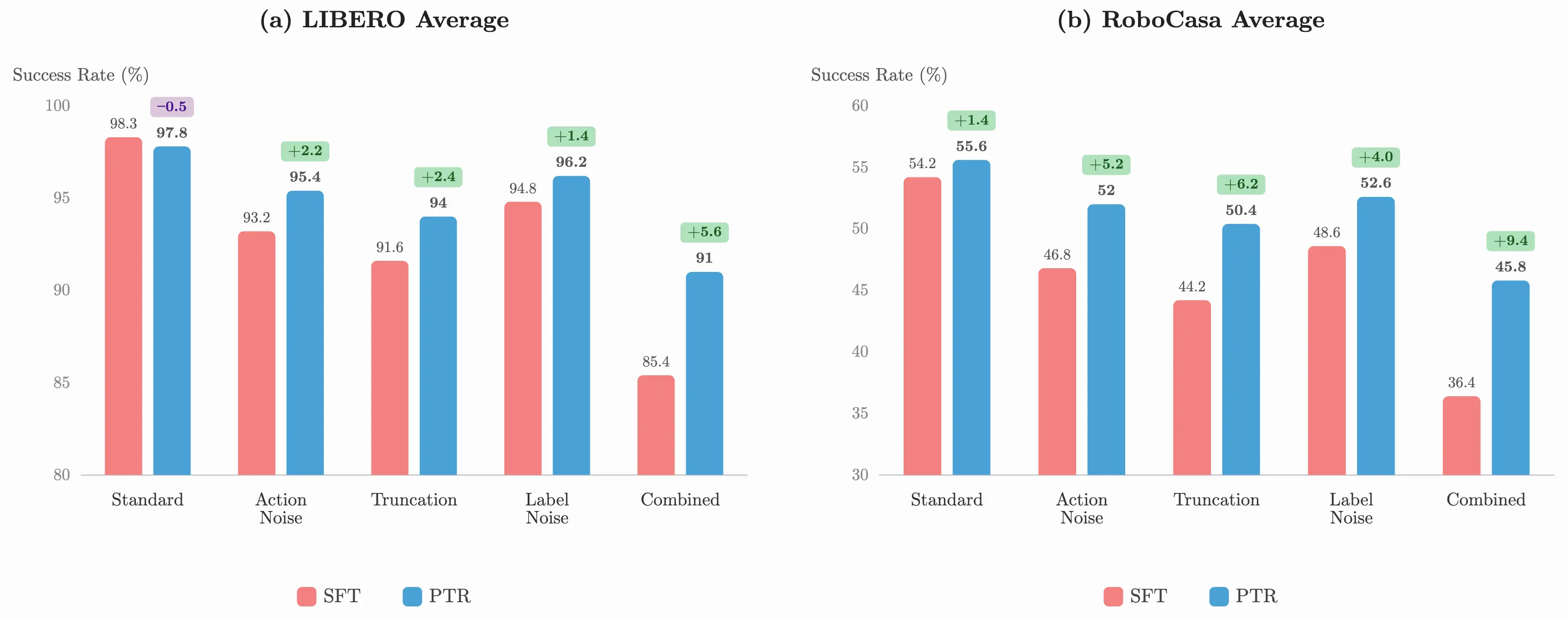
The pattern was consistent. Under the combined corruption (all three at once), standard post-training lost 12.9 pp on LIBERO and 17.8 pp on RoboCasa. PTR lost 6.8 pp and 9.8 pp, roughly half the degradation. The mechanism is straightforward: corrupted samples produce atypical post-action observations that the scorer struggles to identify, so they naturally receive less emphasis. Clean samples with distinctive consequences keep their credit.
On uncorrupted data, PTR stays competitive with standard post-training on LIBERO (where the data is already clean and near-ceiling) and improves on RoboCasa (+1.4 pp), where demonstrations span more diverse kitchen scenes.
Cross-embodiment
The cross-embodiment story is where PTR matters most. Consider two tasks that appear on both Adam-U and FR3: Drawer Organization and Wipe Board. The semantic goal is identical: organize a drawer, wipe a board. But the raw trajectories look completely different: different camera angles, different arm kinematics, different contact dynamics, different action timings.
What these cross-embodiment demonstrations can share is post-action structure: after a successful wipe, the board looks cleaner regardless of which robot did it. PTR picks up on this. When a helper embodiment's demonstration produces a post-action observation that is identifiable under the target embodiment's context, the scorer assigns a high score and the sample gets amplified. When the kinematic mismatch makes the consequence uninformative, the score stays low and the sample reverts to baseline weighting.
The numbers tell the story clearly. Under standard generalist training (pooling all sources into one checkpoint), real-robot success rate dropped from 60.8% to 50.0%, a 10.8 pp collapse from embodiment conflicts. PTR-Generalist held at 63.8%, limiting the drop to just 3.3 pp. The gap between PTR and standard post-training widened from +6.3 pp in specialist training to +13.8 pp in the generalist setting.
One result surprised us: on Long-Horizon tasks, PTR-Generalist (65.0%) actually surpassed the standard specialist checkpoint (63.3%) that was trained on each robot's own data alone. Cross-embodiment data, when filtered by PTR, provided useful coverage for multi-step tasks that the single-embodiment dataset could not.
Real-World Tasks
We evaluated PTR across various tasks on three platforms, spanning bimanual coordination, long-horizon sequencing, spatial precision, and robustness under scene variation.
The largest per-suite gains appeared where operator variability and partial completions are most common: Bimanual and Robust tasks both improved by +11.7 pp under specialist training. In the generalist setting, PTR improved over standard post-training on all 12 tasks, and the generalist PTR checkpoint matched or exceeded the specialist standard checkpoint on 11 of 12.
We also tested under a deliberately challenging out-of-distribution scene: unseen objects, a novel background, flickering overhead lighting, and a transparent bottle that challenges depth perception. The PTR checkpoint still completed the task.

Training Dynamics
The training curves confirm that the scorer is not an unstable add-on. Across six embodiment settings, identification accuracy converges smoothly, the PTR score stabilizes at embodiment-dependent levels, and the action loss decreases normally throughout.
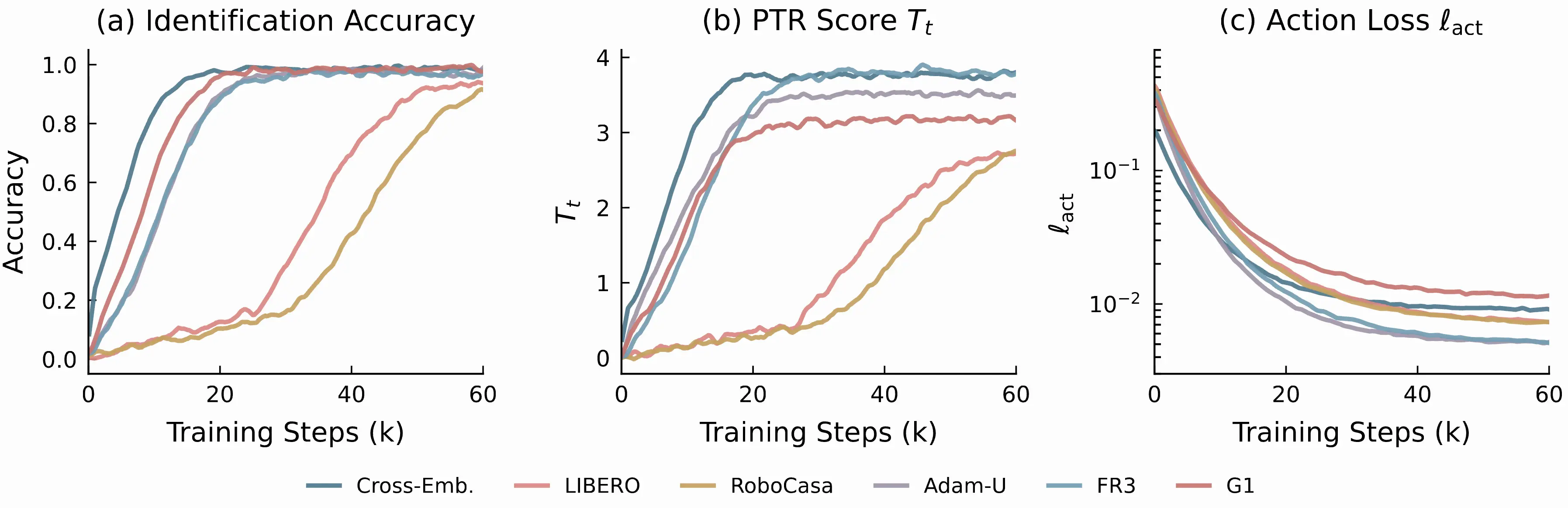
The cross-embodiment joint run achieves the highest final PTR score and identification margin, consistent with a richer candidate pool from five data sources providing more distinctive post-action signatures.
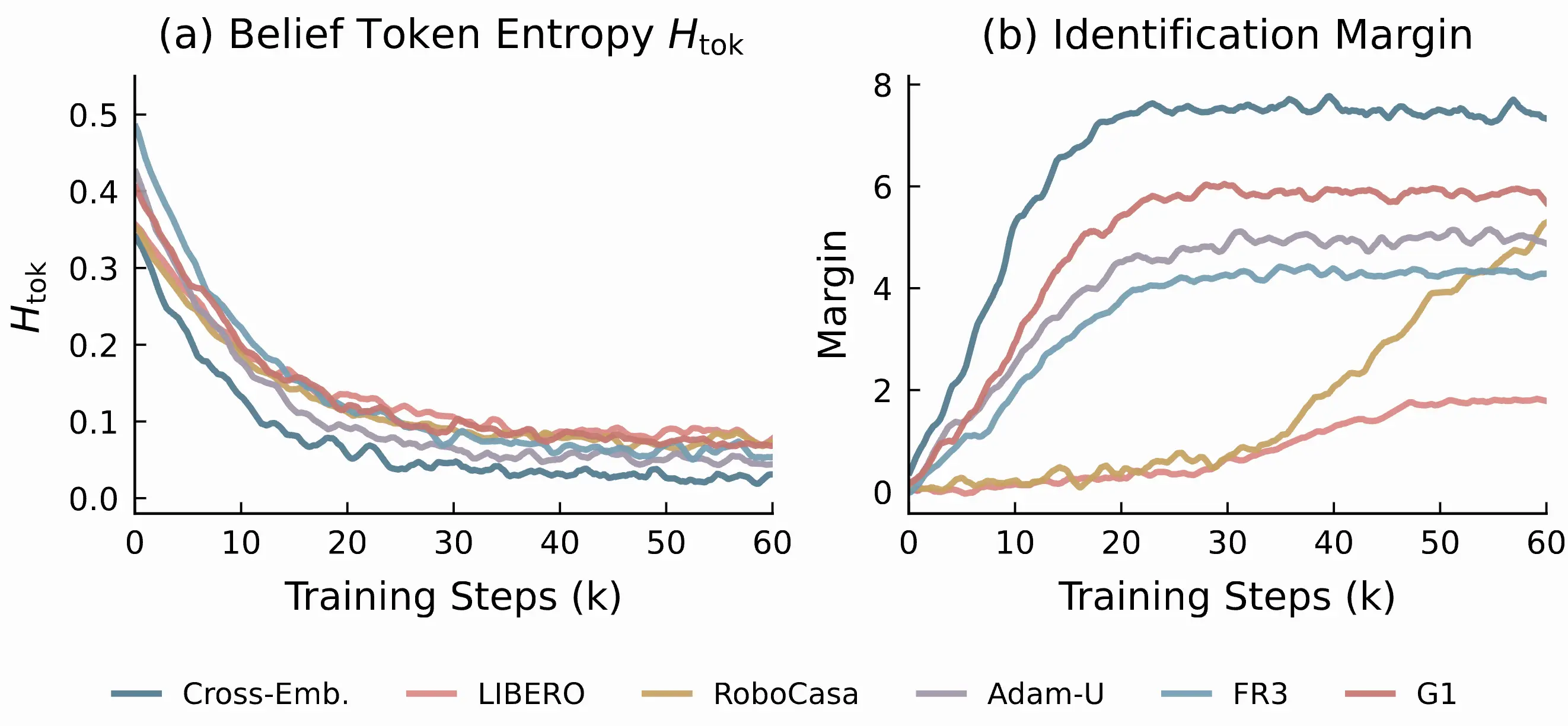
The belief-token entropy drops steadily toward near-zero, showing that the tokenizer converges to compact slot assignments. The identification margin grows throughout training rather than fluctuating, indicating stable scorer maturation.
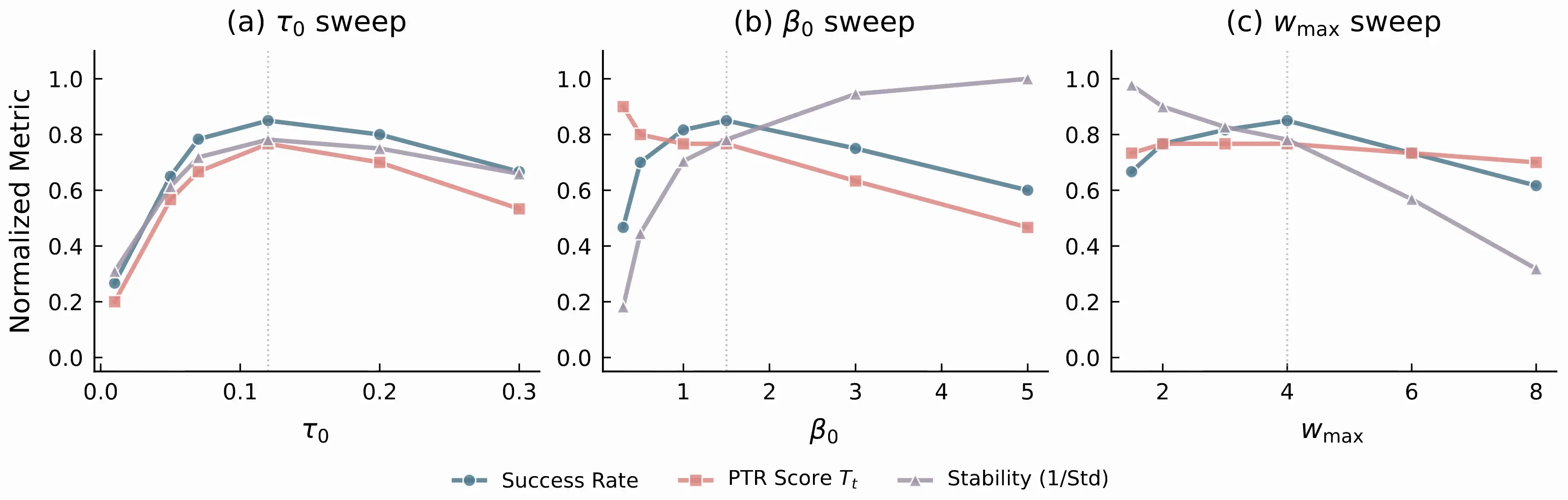
Hyperparameter sweeps show that PTR operates in a broad stable regime rather than depending on a narrow setting. The default configuration (, , ) sits comfortably in the middle of the effective range for all three parameters.
Wrapping Up
PTR started from a concrete frustration: pooling robot data across embodiments kept making things worse. The fix turned out to be surprisingly simple: look at what happened after each action, and ask whether that consequence is recognizable. Actions with distinctive, identifiable consequences receive more weight. Actions with ambiguous or mismatched consequences fall back to baseline. Clipping and self-normalization keep the whole thing bounded.
The method does not need reward labels, does not need a tractable policy likelihood, and does not change the action head. It is a conservative overlay on standard post-training that teaches the training process to be selective about which demonstrations deserve emphasis, and which ones are better left at uniform weight.
Citation
@article{zhang2026conservative,
title={Conservative Offline Robot Policy Learning via Posterior-Transition Reweighting},
author={Zhang, Wanpeng and Luo, Hao and Zheng, Sipeng and Feng, Yicheng and Xu, Haiweng and Xi, Ziheng and Xu, Chaoyi and Yuan, Haoqi and Lu, Zongqing},
journal={arXiv preprint arXiv:2603.16542},
year={2026}
}