

Abstract
While Vision-Language-Action (VLA) models show strong promise for generalist robot control, it remains unclear whether, and under what conditions, the standard "scale data" recipe translates to robotics, where training data is inherently heterogeneous across embodiments, sensors, and action spaces.
We present a systematic, controlled study of VLA scaling that revisits core training choices for pre-training across diverse robots. Using a representative VLA framework that combines a vision-language backbone with flow-matching, we ablate key design decisions under matched conditions and evaluate them in extensive simulation and real-robot experiments.
To improve the reliability of real-world results, we introduce a Grouped Blind Ensemble protocol that blinds operators to model identity and separates policy execution from outcome judgment, reducing experimenter bias.
Our analysis targets three dimensions of VLA scaling:
- Physical Alignment: We show that a unified end-effector (EEF)-relative action representation is critical for robust cross-embodiment transfer.
- Embodiment Mixture: We find that naively pooling heterogeneous robot datasets often induces negative transfer rather than gains, underscoring the fragility of indiscriminate data scaling.
- Training Regularization: We observe that intuitive strategies, such as sensory dropout and multi-stage fine-tuning, do not consistently improve performance at scale.
This study challenges common assumptions about embodied scaling and provides practical guidance for training large-scale VLA policies from diverse robotic data.
Real-World Demonstration
To make the outcome explicit up front, we present paired rollouts for each task: a success case and a failure case. The comparison shows that our rethinking choices lead to more consistently successful real-world execution:
- Stack Bowls: Precision manipulation.
- Pick-to-Drawer: Long-horizon planning.
- Wipe Board: Dynamic motion and surface contact.
- Water Plant: Interaction with non-rigid objects.
Stack Bowls (Success)
Stack Bowls (Failure)
Pick-to-Drawer (Success)
Pick-to-Drawer (Failure)
Wipe Board (Success)
Wipe Board (Failure)
Water Plant (Success)
Water Plant (Failure)
Methodology & Evaluation
1. Mixture-of-Transformers with Flow-Matching
To combine high-frequency, precise control with strong semantic reasoning, we adopt a Mixture-of-Transformers (MoT) design.
- Dual Experts: The model comprises a Semantic Expert (initialized from a VLM to preserve priors) and an Action Expert (trained from scratch). They are connected via Layerwise Shared Attention, allowing the Action Expert to directly attend to the full visual-semantic context.
- Flow Matching: We model action generation as a conditional distribution over action chunks using flow matching, producing smooth trajectories.
2. Physically Grounded Unified Action Space
To support scalable pre-training across heterogeneous robots, we define a physically grounded unified action space . This space acts as a superset of all supported physical degrees of freedom (DoF):
This includes bimanual end-effector poses, joint positions, grippers, dexterous hands, and auxiliary mechanisms. This construction allows the model to learn shared physical priors in overlapping subspaces while retaining embodiment-specific control.
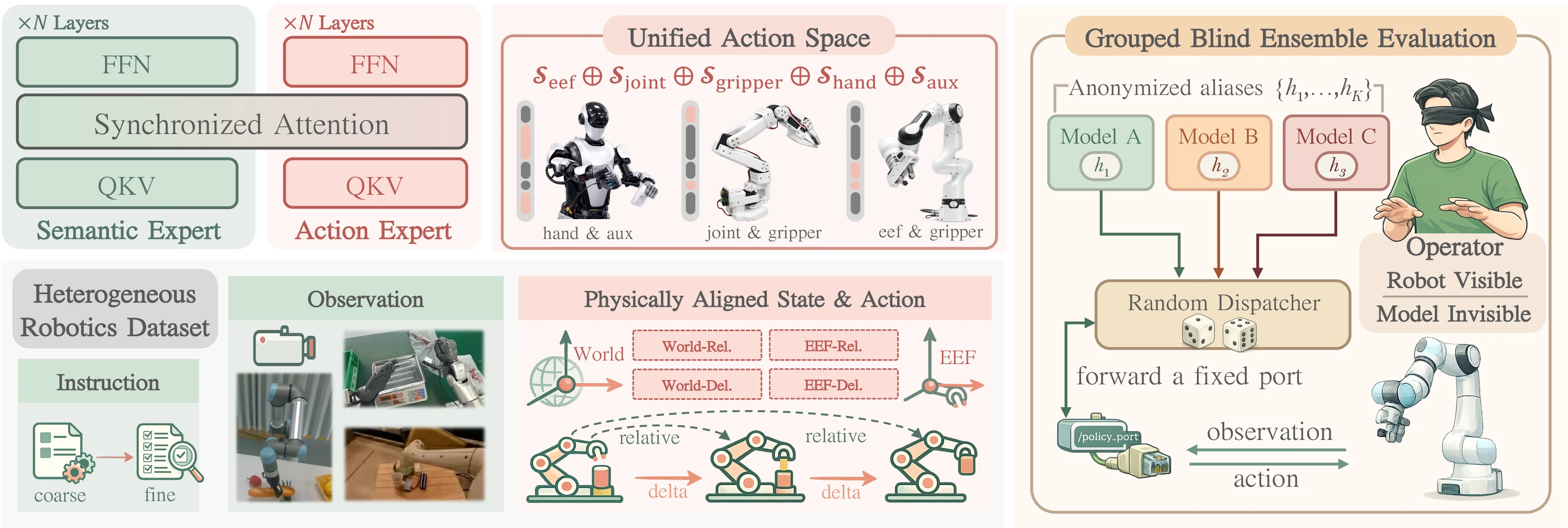
3. Grouped Blind Ensemble Evaluation
Require: Model Pool M, Task Set T, Group Size K, Trials per model N
1. Divide M into random non-overlapping groups {G1, ..., GM}
2. For each task tau in T:
3. For each model group Gj:
4. H <- Anonymize(Gj) # Map models to aliases
5. Q <- Shuffle({h1 x N, ..., hK x N}) # Randomized trial queue
6. Initialize results Rj <- empty
7. While Q is not empty:
8. h <- Q.pop() # Next anonymous model
9. Operator executes task tau with policy pi_h
10. Record outcome r in {0, 1} to Rj
11. Break # Allow operator rest between groups
12. Return deanonymized aggregate statisticsEvaluating robotic foundation models is susceptible to experimenter bias. We propose the Grouped Blind Ensemble Protocol, a double-blind procedure where operators execute tasks without knowing which model variant is running, and outcome judgment is decoupled from execution.
Experiments
We conduct a systematic study centered on three key design dimensions: Physical Alignment, Embodiment Mixture, and Training Regularization.
1. Exploration of Physical Alignment
We evaluate four coordinate parameterizations: World-Relative, World-Delta, EEF-Relative, and EEF-Delta.
- Simulation Results: The coordinate frame strongly influences transfer behavior. On LIBERO, world-frame coordinates can look competitive in scratch training, but pre-training transfer is negative for world-frame variants and consistently positive for EEF-frame variants. In the frozen-VLM setting, EEF-Relative reaches the highest average success rate (75.1%) with the largest improvement (+8.2%).
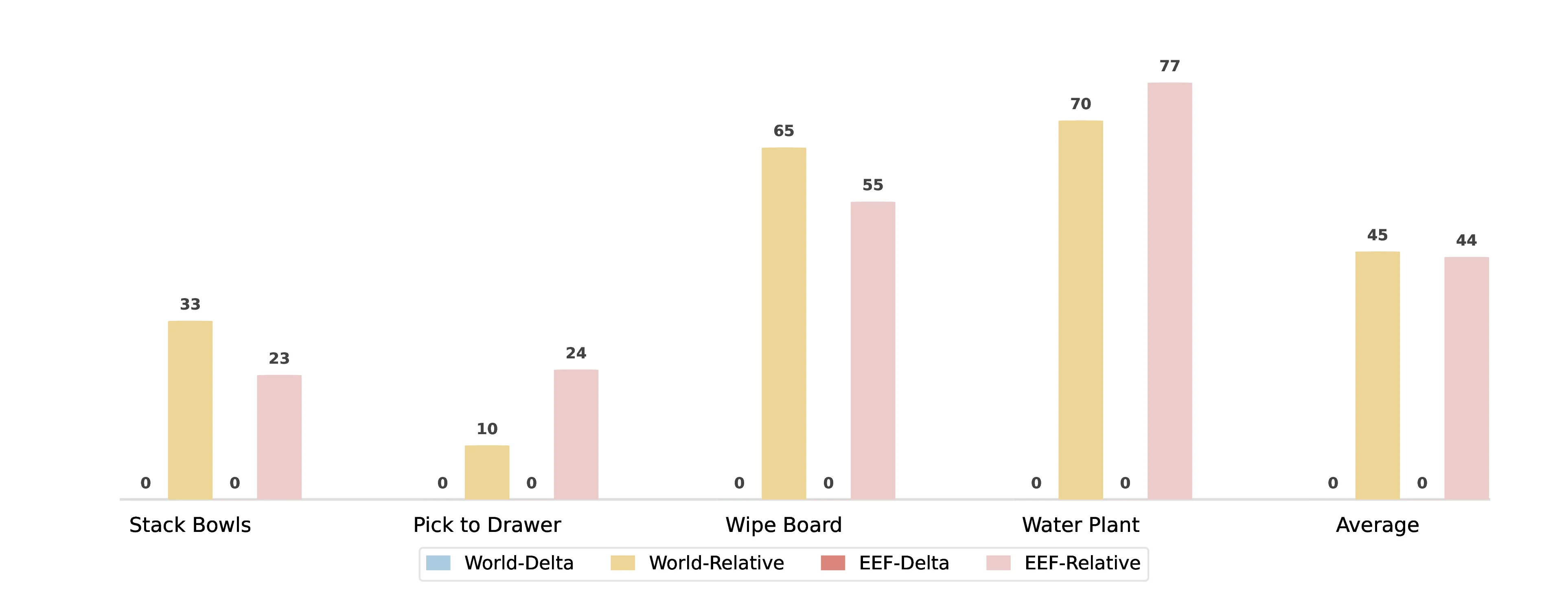
- Real-World Results: EEF-Delta actions exhibit severe jittering and become unusable in real-robot deployment (0% in blind evaluation), while relative-coordinate variants execute effectively; in this setting, World-Relative and EEF-Relative show no significant performance gap.
Table II: Action Space Ablation on LIBERO
Unfrozen VLM
| Action Space | Init. | Spatial | Object | Goal | Long | Avg |
|---|---|---|---|---|---|---|
| World-Relative | Scratch | 90.8 | 93.6 | 78.2 | 74.8 | 84.4 |
| World-Relative | Pretrain | 89.8 (-1.0) | 86.8 (-6.8) | 88.4 (+10.2) | 68.8 (-6.0) | 83.5 (-0.9) |
| World-Delta | Scratch | 90.4 | 93.0 | 82.8 | 73.6 | 85.0 |
| World-Delta | Pretrain | 86.2 (-4.2) | 92.0 (-1.0) | 88.8 (+6.0) | 71.0 (-2.6) | 84.5 (-0.5) |
| EEF-Relative | Scratch | 87.6 | 93.0 | 76.4 | 70.6 | 81.9 |
| EEF-Relative | Pretrain | 86.0 (-1.6) | 90.0 (-3.0) | 88.6 (+12.2) | 73.4 (+2.8) | 84.5 (+2.6) |
| EEF-Delta | Scratch | 87.6 | 93.0 | 72.0 | 67.0 | 79.9 |
| EEF-Delta | Pretrain | 85.6 (-2.0) | 89.8 (-3.2) | 87.4 (+15.4) | 66.2 (-0.8) | 82.3 (+2.4) |
Frozen VLM
| Action Space | Init. | Spatial | Object | Goal | Long | Avg |
|---|---|---|---|---|---|---|
| World-Relative | Scratch | 72.2 | 85.0 | 75.4 | 43.6 | 69.1 |
| World-Relative | Pretrain | 81.2 (+9.0) | 89.8 (+4.8) | 75.0 (-0.4) | 52.6 (+9.0) | 74.7 (+5.6) |
| World-Delta | Scratch | 74.2 | 75.0 | 75.0 | 42.6 | 66.7 |
| World-Delta | Pretrain | 82.6 (+8.4) | 89.6 (+14.6) | 73.8 (-1.2) | 53.2 (+10.6) | 74.8 (+8.1) |
| EEF-Relative | Scratch | 73.0 | 84.2 | 70.6 | 39.6 | 66.9 |
| EEF-Relative | Pretrain | 79.8 (+6.8) | 90.6 (+6.4) | 76.6 (+6.0) | 53.2 (+13.6) | 75.1 (+8.2) |
| EEF-Delta | Scratch | 73.2 | 79.8 | 70.4 | 41.0 | 66.1 |
| EEF-Delta | Pretrain | 77.8 (+4.6) | 88.2 (+8.4) | 73.6 (+3.2) | 48.4 (+7.4) | 72.0 (+5.9) |
Table III: Action Space Ablation on RoboCasa
| Group | Action Space | Init. | Pick/Place | Doors/Drawers | Other | Avg |
|---|---|---|---|---|---|---|
| World-Frame Coordinates | World-Relative | Scratch | 20.0 | 60.0 | 40.0 | 38.3 |
| World-Frame Coordinates | World-Relative | Pretrain | 22.5 (+2.5) | 58.3 (-1.7) | 45.0 (+5.0) | 40.8 (+2.5) |
| World-Frame Coordinates | World-Delta | Scratch | 21.0 | 62.3 | 46.0 | 41.8 |
| World-Frame Coordinates | World-Delta | Pretrain | 23.8 (+2.8) | 60.0 (-2.3) | 45.0 (-1.0) | 41.7 (-0.1) |
| End-Effector Coordinates | EEF-Relative | Scratch | 33.0 | 57.3 | 47.4 | 45.1 |
| End-Effector Coordinates | EEF-Relative | Pretrain | 35.3 (+2.3) | 62.3 (+5.0) | 54.4 (+7.0) | 50.0 (+4.9) |
| End-Effector Coordinates | EEF-Delta | Scratch | 26.0 | 63.7 | 44.8 | 43.3 |
| End-Effector Coordinates | EEF-Delta | Pretrain | 36.3 (+10.3) | 56.7 (-7.0) | 49.0 (+4.2) | 46.7 (+3.4) |
2. Exploration of Embodiment Mixture
With the action space fixed to EEF-Relative, we study the effect of scaling heterogeneous pre-training data. We constructed four progressively richer data mixtures:
- D1 (OXE Only): Standard public datasets.
- D2 (+Real EEF): Adding diverse real-world proprietary data.
- D3 (+Sim EEF): Further including simulation EEF data.
- D4 (+Joint): Additionally incorporating joint-space data projected into the unified model.
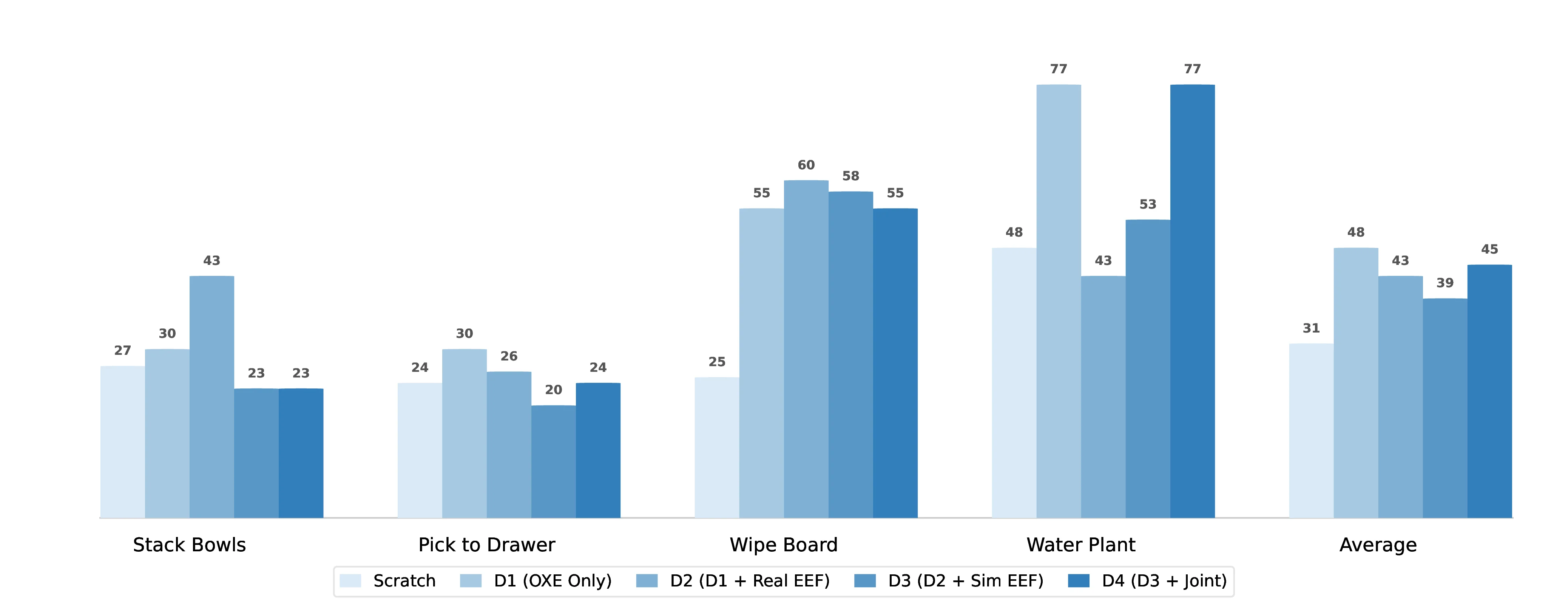
Unlike language model scaling, increasing robotic corpus size does NOT yield monotonic gains.
- Negative Transfer: Naively pooling heterogeneous real and simulation data (D2, D3) often degrades performance. For instance, on RoboCasa, D2 drops performance to 48.8% compared to D1's 54.7%.
- Fragility of Scaling: While projecting joint-space data in D4 recovers some of the performance lost in D2 and D3, the final mixture often fails to surpass the high-quality D1 baseline. This highlights that simply pooling structurally disparate robot datasets can induce destructive interference.
- Real-World Results: In blind real-robot evaluation, all pre-training mixtures (D1-D4) outperform training from scratch, while D1 remains the most robust setting. Adding simulated EEF trajectories introduces task-dependent degradation, especially on Stack Bowls, Pick-to-Drawer, and Wipe Board.
Table IV: Data Mixture Ablation on LIBERO
Frozen VLM
| Pre-train Mixture | Spat | Obj | Goal | Long | Avg |
|---|---|---|---|---|---|
| Scratch | 73.0 | 84.2 | 70.6 | 39.6 | 66.9 |
| : OXE Only | 87.6 (+14.6) | 88.2 (+4.0) | 78.8 (+8.2) | 54.6 (+15.0) | 77.3 (+10.4) |
| : + Real EEF | 84.4 (-3.2) | 86.0 (-2.2) | 77.4 (-1.4) | 47.4 (-7.2) | 73.8 (-3.5) |
| : + Sim EEF | 76.0 (-8.4) | 82.2 (-3.8) | 79.0 (+1.6) | 51.2 (+3.8) | 72.1 (-1.7) |
| : + Joint | 79.8 (+3.8) | 90.6 (+8.4) | 76.6 (-2.4) | 53.2 (+2.0) | 75.1 (+3.0) |
Unfrozen VLM
| Pre-train Mixture | Spat | Obj | Goal | Long | Avg |
|---|---|---|---|---|---|
| Scratch | 87.6 | 93.0 | 76.4 | 70.6 | 81.9 |
| : OXE Only | 89.2 (+1.6) | 89.2 (-3.8) | 92.8 (+16.4) | 74.4 (+3.8) | 86.4 (+4.5) |
| : + Real EEF | 86.2 (-3.0) | 94.6 (+5.4) | 88.8 (-4.0) | 66.4 (-8.0) | 84.0 (-2.4) |
| : + Sim EEF | 87.4 (+1.2) | 91.4 (-3.2) | 86.2 (-2.6) | 69.6 (+3.2) | 83.7 (-0.3) |
| : + Joint | 86.0 (-1.4) | 90.0 (-1.4) | 88.6 (+2.4) | 73.4 (+3.8) | 84.5 (+0.8) |
Table V: Data Mixture Ablation on RoboCasa
| Pre-train Mixture | Pick/Place | Doors/Drawers | Other | Avg |
|---|---|---|---|---|
| Scratch | 33.0 | 57.3 | 47.4 | 45.1 |
| D1: OXE Only | 42.0 (+9.0) | 72.3 (+15.0) | 54.2 (+6.8) | 54.7 (+9.6) |
| D2: D1 + Real EEF | 38.5 (-3.5) | 60.5 (-11.8) | 47.4 (-6.8) | 48.8 (-5.9) |
| D3: D2 + Sim EEF | 36.3 (-2.2) | 56.7 (-3.8) | 56.0 (+8.6) | 49.6 (+0.8) |
| D4: D3 + Joint | 35.3 (-1.0) | 62.3 (+5.6) | 54.4 (-1.6) | 50.0 (+0.4) |
3. Exploration of Training Regularization
We evaluate the impact of sensory dropout (view/proprioception masking) and multi-stage training curricula.
- Limited Benefit: Stochastic modality dropout does not consistently improve performance. Disabling visual dropout () actually achieved higher success (85.6%) than the balanced baseline.
- Simplicity Wins: A two-stage curriculum is not essential. Direct end-to-end fine-tuning of the full model reached the best average success (85.8%), indicating that the action expert quickly co-adapts with the VLM backbone.
Table VI: Analysis of Training Dynamics and Strategies
| State Mask | View Mask | Schedule | Spat | Obj | Goal | Long | Avg |
|---|---|---|---|---|---|---|---|
| 0.2 | 0.2 | 2-Stage | 86.0 | 90.0 | 88.6 | 73.4 | 84.5 |
| 0 | 0.2 | 2-Stage | 88.2 | 96.0 | 87.6 | 69.0 | 85.2 |
| 0.5 | 0.2 | 2-Stage | 88.8 | 90.4 | 86.8 | 70.0 | 84.0 |
| 0.2 | 0 | 2-Stage | 87.0 | 92.2 | 89.2 | 74.0 | 85.6 |
| 0.2 | 0.5 | 2-Stage | 85.8 | 93.2 | 86.6 | 72.2 | 84.5 |
| 0.2 | 0.2 | Stage 2 Only | 88.2 | 93.8 | 87.0 | 74.0 | 85.8 |
4. Comparison with Generalist Policies
To validate that our testbed is representative of modern VLA capabilities, we benchmarked it against , , and GR00T-N1 under a matched 50-shot fine-tuning protocol.
Our base model is highly competitive without task-specific tuning or specialized optimizations, achieving 97.9% average success on LIBERO and 50.0% on RoboCasa. This confirms that our experimental conclusions are drawn from a high-performance regime aligned with current state-of-the-art robot learning.
Table VII: Comparison with Representative Generalist Policies
LIBERO
| Model | Spatial | Object | Goal | Long | Avg |
|---|---|---|---|---|---|
| GR00T-N1 | 94.4 | 97.6 | 93.0 | 90.6 | 93.9 |
| 98.0 | 96.8 | 94.4 | 88.4 | 94.4 | |
| 98.8 | 98.2 | 98.0 | 92.4 | 96.9 | |
| Ours (Base) | 98.4 | 96.2 | 98.4 | 98.2 | 97.9 |
RoboCasa
| Model | Pick/Place | Doors/Drawers | Other | Avg |
|---|---|---|---|---|
| GR00T-N1 | 18.6 | 50.2 | 39.1 | 36.0 |
| 14.0 | 53.1 | 58.5 | 42.4 | |
| 21.5 | 57.8 | 44.9 | 41.4 | |
| Ours (Base) | 35.3 | 62.3 | 54.4 | 50.0 |
Conclusion
In this work, we present a systematic study on scaling Vision-Language-Action (VLA) models with heterogeneous robot data. To ensure reliable evaluation, we introduce a Grouped Blind Ensemble protocol that minimizes human bias in real-world experiments.
This study provides a reality check on VLA scaling:
- EEF-Relative action space establishes itself as a reliable default for handling diverse robot kinematics.
- Scaling cross-embodiment data is challenging. Indiscriminately mixing heterogeneous robotic data (Real/Sim/Joint) frequently degrades performance rather than improving it, highlighting the fragility of naive data scaling.
- Simple training recipes are sufficient. Complex regularization strategies do not reliably translate into gains at scale.
Overall, our work suggests that future VLA research must move beyond simple data accumulation and focus on addressing the interference caused by embodiment heterogeneity.
Citation
@article{wang2026rethinking,
title={Rethinking Visual-Language-Action Model Scaling: Alignment, Mixture, and Regularization},
author={Wang, Ye and Zheng, Sipeng and Luo, Hao and Zhang, Wanpeng and Yuan, Haoqi and Xu, Chaoyi and Xu, Haiweng and Feng, Yicheng and Yu, Mingyang and Kang, Zhiyu and others},
journal={arXiv preprint arXiv:2602.09722},
year={2026}
}