

VIPA-VLA learns 2D-to-3D visual-physical grounding from human videos with Spatial-Aware VLA Pretraining, enabling robot policies with stronger spatial understanding and generalization.
Framework
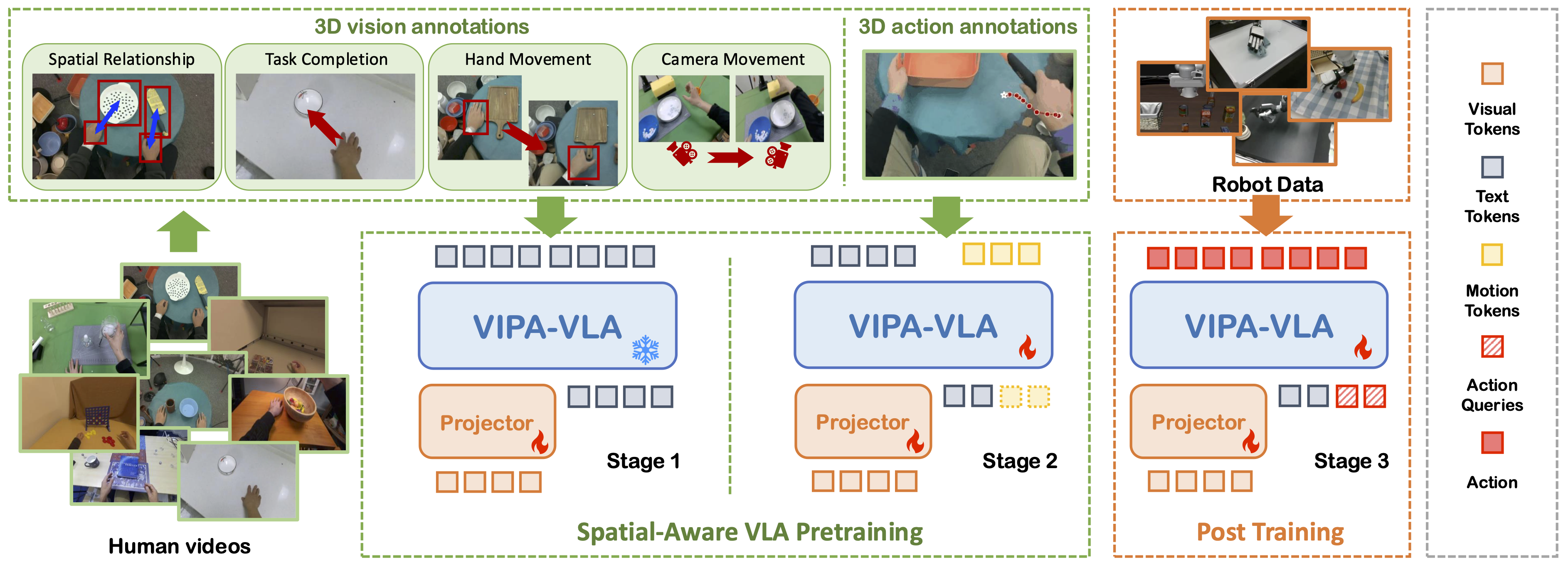
VIPA-VLA follows a three-stage training framework designed to endow VLA models with strong 3D spatial understanding before learning robot actions: (1) 3D-Visual-Pretraining: Starting from a VLM backbone, we use human demonstration videos with 3D visual annotations to align 2D visual features with 3D spatial representations through a dual-encoder fusion module. (2) 3D-Action-Pretraining: We further learn 3D motion priors from human hand trajectories, discretizing wrist motion into action tokens that capture how humans interact physically with the world. (3) Robot Post-Training: Finally, the pretrained model is adapted to robot manipulation tasks using robot demonstrations, enabling efficient learning and strong generalization in both simulation and real-world environments.
Dataset
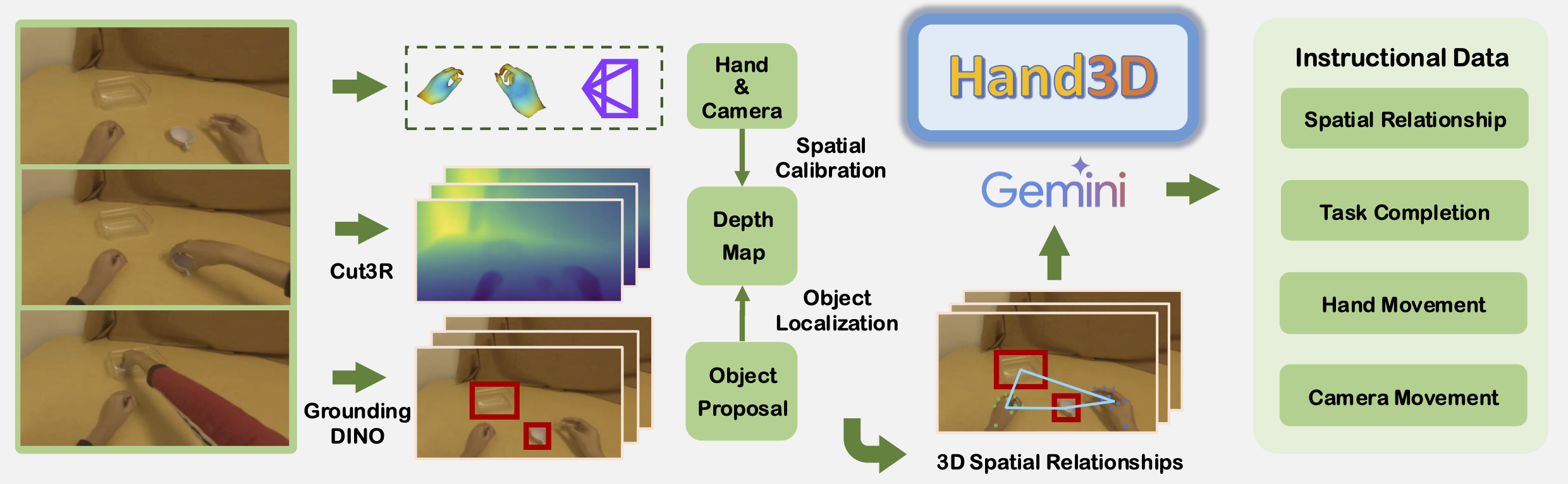
We introduce Hand3D, a large-scale collection of human manipulation videos enriched with 3D visual and action annotations. The dataset captures diverse hand-object-camera interactions across varied scenes and tasks, providing rich 2D-to-3D correspondences that serve as powerful supervision for Spatial-Aware Pretraining.
Architecture
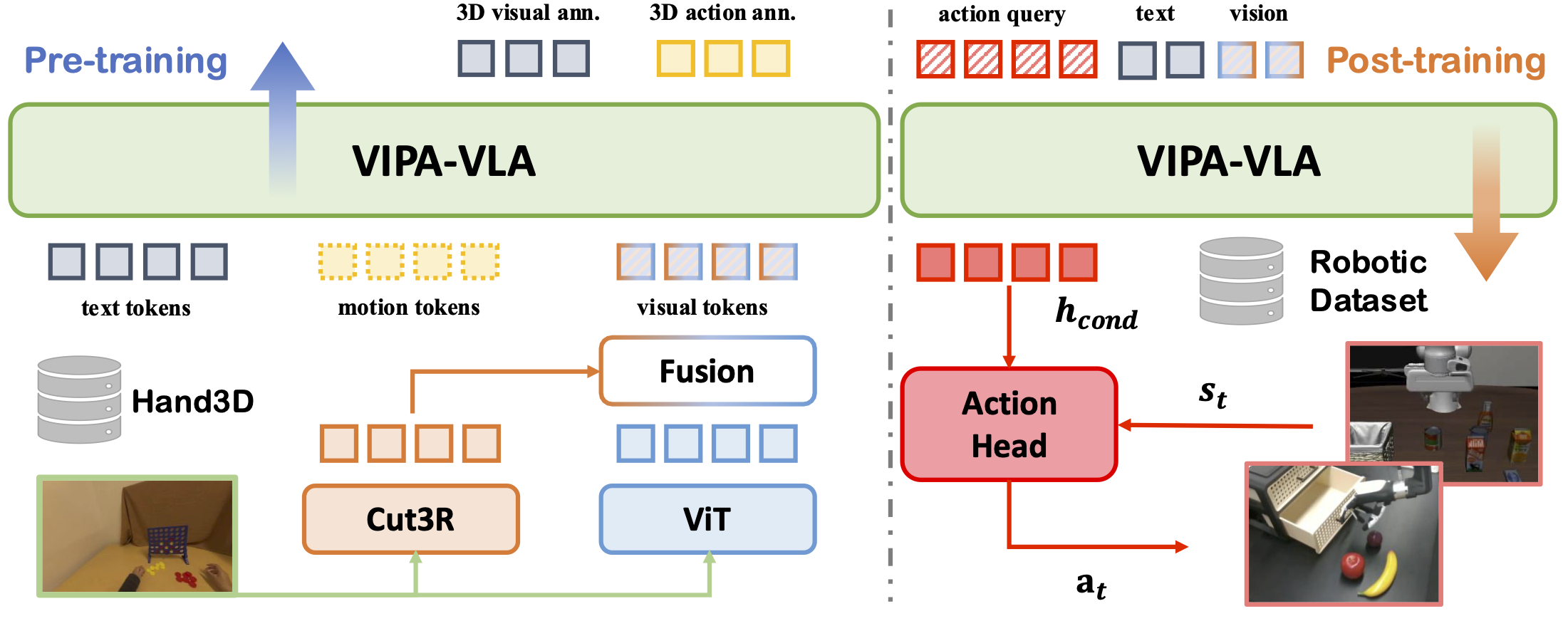
VIPA-VLA adopts a dual-encoder design that integrates a semantic visual encoder with a 3D spatial encoder. A lightweight fusion module aligns and combines their representations through cross-attention, producing spatially grounded features. During post-training, an action query interacts with these fused features, and a flow-matching action head predicts continuous 3D actions conditioned on robot states.
Features
3D Action Prediction
VIPA-VLA can predict 3D wrist trajectories after pretrained with 3D action annotations (the red lines are ground-truth human trajectories, while the blue lines are wrist trajectories predicted by VIPA-VLA). Across diverse manipulation scenes, the model accurately infers how visual observations correspond to physical motion, producing smooth and task-aligned trajectories. Notably, VIPA-VLA filters out noisy human hand motions and captures the essential manipulation intent-such as approaching objects along feasible paths or grasping tools at appropriate contact points-demonstrating strong spatial grounding and action understanding.
Real-World Robot Performance
For real-robot execution, VIPA-VLA can complete tasks with accurate spatial grounding-reliably localizing objects and following multi-step goals. Baselines-trained without Spatial-Aware VLA Pre-training and without our dual-encoder architecture-frequently exhibit spatial misalignment, such as misjudging object positions, reaching toward incorrect regions, or producing inconsistent trajectories that reflect poor 2D-3D correspondence.
VIPA-VLA:
Baseline:
Citation
@inproceedings{feng2026spatialaware,
title={Spatial-Aware VLA Pretraining through Visual-Physical Alignment from Human Videos},
author={Yicheng Feng and Wanpeng Zhang and Ye Wang and Hao Luo and Haoqi Yuan and Sipeng Zheng and Zongqing Lu},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}